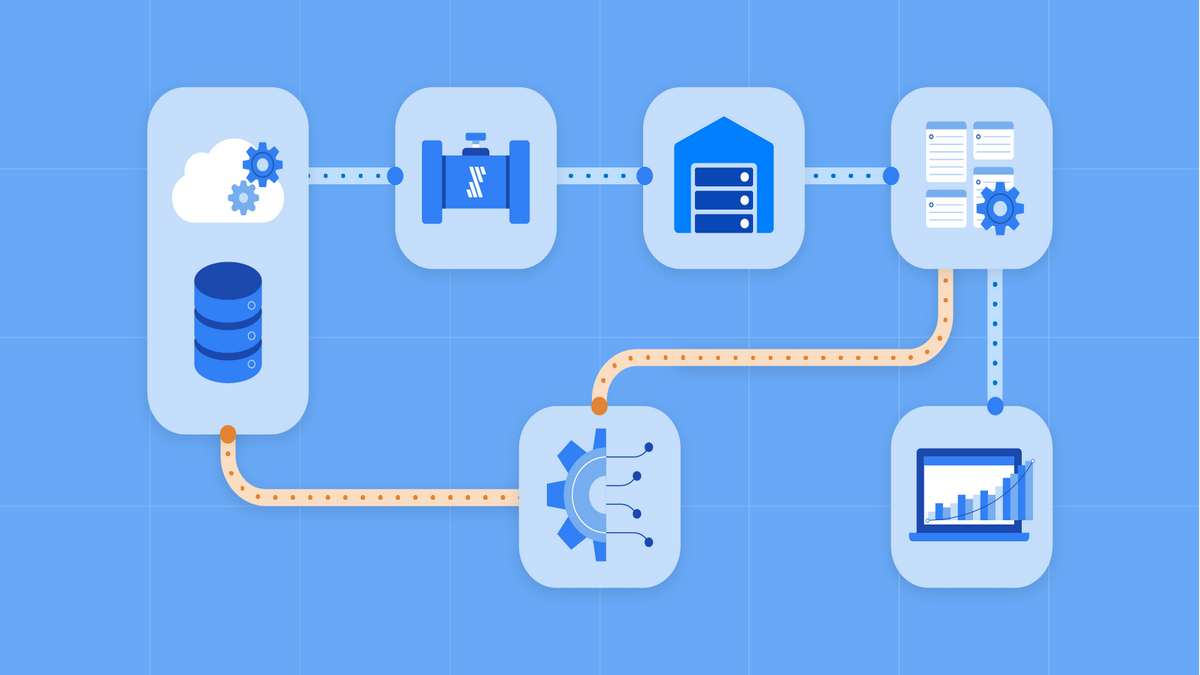
Data analytics are extremely valuable in modern business. If you want to take your organization to the next level, you need to use actionable data. However, the process of gathering, managing, storing, and analyzing data can get really complex and present various challenges.
The whole process needs to be efficient to get tangible results, and the longer it takes for an organization to process data, the more it costs. In other words, companies can easily get trapped in these tasks affecting their business negatively.
It’s imperative to load and move data quickly. That’s where ETL and ELT are crucial, but even these processes are no longer sustainable, especially for smaller organizations.
What are the requirements companies have for data?
Connecting with different data formats
Companies always have different data formats they need to handle but often don’t have the required connectors or simply have to spend a lot of resources on creating custom solutions that can support them. Even when those systems are set in place, the moving speeds are generally slow.
Fast insights
Time to insight is a crucial data metric. Companies often do time-sensitive tasks, so they need to get their insights on time to make the right decisions. If not, their data analytics process becomes redundant.
SQL querying
Many companies have their engineers and analysts under heavy workloads, making it impossible to learn new technologies and get the resources they require. At the same time, hiring experts can be expensive.
Removing data silos usage
Using multiple data silos sources leads to many difficulties like determining the right place to start the process, data sharing, and inconsistencies.
Most organizations use ETL & ELT
Companies rely extensively on complex reporting structures and large volumes of data. Many companies can’t effectively access all of this data since it’s stored in multiple locations. Data visualization and data analytics need proper preparation, and it’s impossible to create reports in real-time to deliver value.
These complexities around data led to the implementation of ETL/ELT solutions for extracting big data insights. These tools come in many different forms, and their job is to collect data from many sources, change its format, and load it into a specific warehouse.
However, even though they are helping, the process takes a lot of time since most companies have traditional data structures. That’s why data professionals are looking for different solutions like “query in place” and reverse ETL solutions.
Today we’re going to talk about query in place solutions. If you want to learn more about reverse ETL, check out this article: https://www.rudderstack.com/blog/reverse-etl-is-just-another-data-pipeline/
New ways of doing ETL/ELT
Data technologies, processes, and methods are constantly evolving. The whole community is aware of the need for better solutions and faster processing speeds. Open-source tools are already appearing across the globe to deal with these issues.
One option that has already proven itself to be effective is distributed query engines. These platforms are designed for running analytical queries on all kinds of data sources. Instead of relying on internal storage, these solutions can connect to almost all storage types and read their data – this feature is called query in-place analysis.
However, these platforms also write data if needed making it even more versatile. You can collect these solutions to SQL, NoSQL databases, S3, and HDFS. A query-in-place solution works with various raw data saving a lot of time needed for pre-processing and preparation that ETL and ELT solutions require.
No matter where the data resides, it can instantly provide insight when stored in the data lake. It’s also possible to work with multiple data sources simultaneously.
More effective query optimization
These new solutions have various features that make data planning and querying more efficient. With table statistics and resource availability analysis, they can choose the most efficient option on their own and reduce the time required when possible.
Many of these systems also have dynamic filtering through which filtering is executed before anything else, including merging tables. All of that leads to much faster query execution.
Bottom line
The dispute around ETL vs. ELT is a thing of the past, and new solutions are knocking on the door of data processing. Companies need to keep up with the latest developments and find platforms that they can seamlessly integrate into their data pipelines at an efficient rate.