To understand how the VISC paradigm works, we have to take into account two different concepts regarding CPU performance. The first of these is the fact that PC CPUs today have an internal instruction set even smaller than RISC, since what they do is transfer each of the instructions in smaller microinstructions internally during the process. decoding phase. If we are purists, the conclusion today all processors is not that they are RISC, but that they have a very reduced set of instructions that works internally and that serves to build the rest of the instructions. That is, as soon as an instruction reaches the CPU control unit it is broken down into a list of instructions.
So the war between RISC and CISC was won by the former, but with the trap that x86, the most widely used CISC architecture, made the trap of behaving internally like a RISC. To this day, except for ARM, the rest of the ISA RISC are missing or on the verge of disappearance. What’s more, even ARM has adopted the concept of dividing the instructions into simpler ones, so both paradigms outside of defining the common ISA of a family are already extinct.
Amdahl’s Law
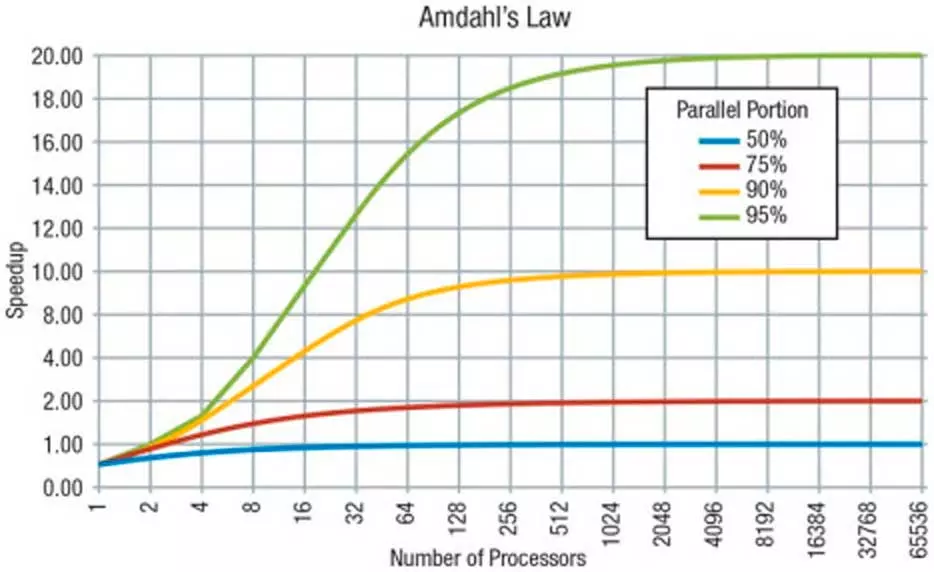
To understand a program we have to understand that a program has two different parts:
- The one that can only be executed in series and, therefore, can only be solved by a single kernel by executing a solo execution kernel.
- That part of the code that can be executed in parallel, which means that it can be solved by several cores at the same time and the more of them there are in the processor, the faster this part will be solved.
If we take into account what was explained in the previous section then you will conclude that some of the processor instructions that become microcode what they do is become a succession of instructions that can work in series or in parallel between several cores, although the usual is that most of the instructions are executed in a single kernel and that it is by shared elements that the code is executed in parallel.
Therefore, the fact that a part of the code is executed by several cores depends exclusively on the program developer, who has to explicitly program it so that certain parts work in parallel.
VISC and virtual cores
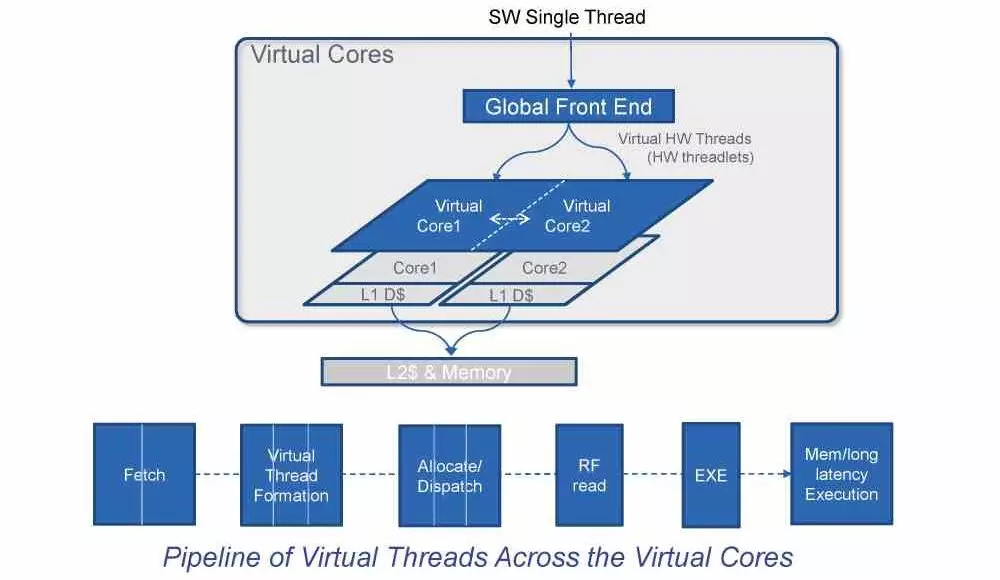
Once we have already explained all of the above, then we can explain what the acronym VISC means, whose definition is the direct answer to the following question: When generating the microinstructions in the decoding stage, cannot they work? in parallel with several cores instead of doing it in a single ditto?
Well, the answer to the question about the VISC architecture, which was first raised by a company called Soft Machines in 2015 as a concept to improve CPU performance. This small startup was bought by Intel in 2016 and since then they have been working on developing a VISC architecture. How does it work? Well, it can be defined very easily: a single thread of execution is sent to the Global Front End of the processor, which is converted into several that perform the same function and that work in parallel and run in virtual cores. The conversion process is executed at the software level through a translation layer, but we must bear in mind that this can be something as simple as a microcontroller carrying out the transfer of the instructions.
Contrary to what happens in the distribution of tasks in a conventional multicore processor, in a VISC architecture it is not intended that a core is free to execute an instruction, but that the elements to execute it are available within the processor to execute it. For example, it may happen that in a conventional kernel the vector unit is not being used, but under this paradigm it can be used to form one of the instructions.
VISC and performance
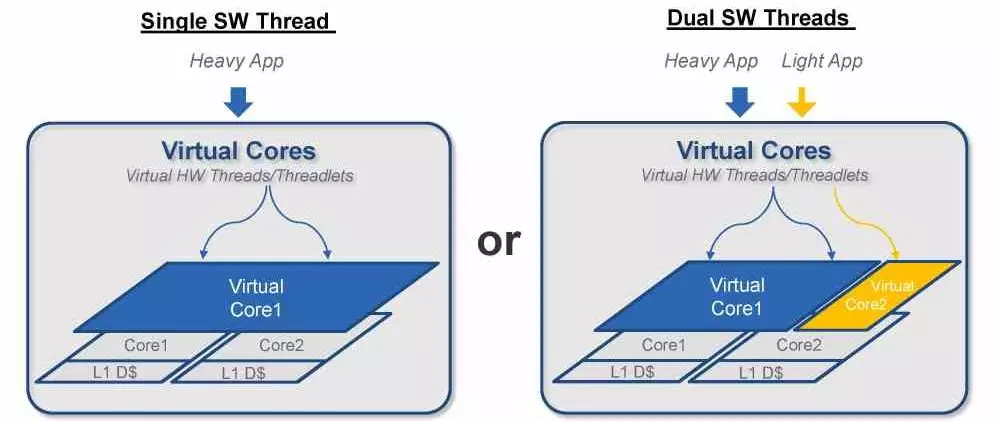
When adopting a new paradigm in terms of architecture, the first thing to consider is how it affects performance, since it is not worth changing the current paradigm if it does not result in an increase in overall processor performance. The most classic way to increase the performance of a processor is to increase the number of instructions that are solved per clock cycle, this means making hardware increasingly complex, due to the fact that the addition of the cores we have to count all the infrastructure that surrounds them that becomes the same or more complex.
What differentiates VISC from the rest is none other than the distribution of processor resources for the execution of the different instructions is carried out in a few clock cycles, between 1 and 4 cores. In this way, if there are two instructions competing for other resources in a core, then they can be reassigned very quickly to another part of the processor where those same resources are available.
The current paradigm, which is the execution out of order, what it does is reorder the execution of the instructions according to the free resources at all times and then reorder the output of already processed data. The limitation? Resource allocation is performed at the single-core rather than multi-core level, and this is the key to higher performance for VISC architectures.
Do these processors exist today?

Although the concept is very good on paper, no one has yet presented a processor that works under this paradigm, but given that we are gradually approaching the limits of the current paradigm, it is important to bear in mind that there are solutions that can serve to improve the CPU performance of our PCs for the future.
Having a more powerful processor is not only having a faster one or with more cores, but it is based on knowing how to take advantage of available resources. The execution out of order was the first step in that sense, however since then outside of going to multicore the changes have been generally minor. VISC is still a concept, however it is not an impossible one and it is a way to take advantage of the resources available in the processor in a much more efficient way.
So far we know that the concept is possible in a CPU since Soft Machines designed and built one with this paradigm, so although it was at an experimental level we know that it is possible to carry out such a design. Another different thing is the difficulty of bringing the entire set of x86 instructions and registers to this paradigm, which is extremely complex by its nature.