
One of the biggest challenges when designing a processor is the energy consumption that occurs when processing information and moving information. The problem comes when in recent years all the engineering effort has not been focused on getting the fastest execution units, but on having enough communication so that the processing is fast enough.
Regardless of whether a computer uses the Harvard or Von Neumann model, it will need a memory that the processor accesses to work. In the simplest systems this memory is located on a separate chip and must be accessed through an interconnection or cable. Well, the big problem appears when we take into account a series of basic principles.
The first and most important is the fact that the resistance in a cable increases the longer it is, if we take into account Ohm’s Law we will know that the voltage is the result of multiplying the resistance by the intensity. What does this have to do with semiconductors? Let’s not forget that they are small-scale electrical circuits and therefore if the distance from which the data is to operate increases, the energy consumption will increase.
The reason for this is found in the basic formula to calculate energy consumption, which is: P = V2* C * f. Where V is the voltage, C is the load capacity that the semiconductor can withstand and f is the frequency. Well, we have seen how the voltage grows with the resistance and we have to add that it also grows with the clock speed.
Vertical interconnections
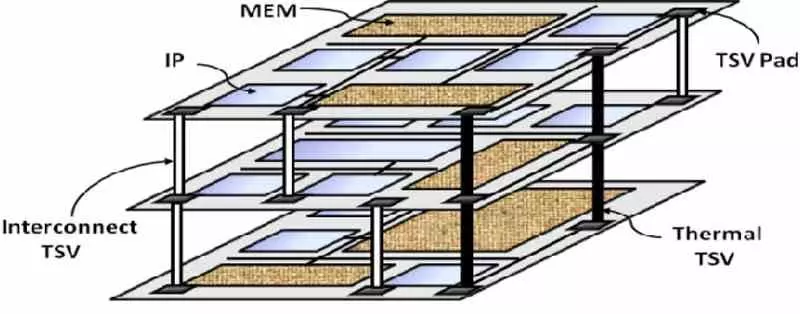
Now that we have the basic principle we find that the solution is to shorten the cables to bring the memory closer to the processing. From the outset we find a limitation and it is none other than the communication between CPU and RAM occurs horizontally on the PCB and routing the communication interface corresponding to each end, so that at a point we will not be able to continue reducing the distance.
Since energy consumption increases exponentially with clock speed, then the best solution is to increase the number of interconnections existing in the communication interface, but we are limited by its size and since it is located on the perimeter of the processor this means increase its size, which makes it more expensive to manufacture. The solution? Place said memory above the chip, in such a way that we can have a matrix wiring.
Both things combined allow us to increase the number of interconnections, which to achieve the same bandwidth allows us to reduce the clock speed, but we also have the advantage that we have reduced the distance of the communication cabling, so we also reduce consumption at that point. The result? Reduce the energy cost of data traffic by 10%.
The LLC problem and consumption

In a multicore design, let’s be talking about a CPU or a GPU, there is always a cache called LLC or last level that is the furthest from the processor, but the closest to the memory, its work is:
- Give consistency in addressing the memory of the different cores that are part of it.
- Allow communication between the different cores without having to do it in RAM, thus reducing consumption.
- It allows the different cores that are part of it to access a common memory well.
The problem comes when in a design we decide to separate several cores from each other to create several chips, but without losing the functionality as a whole for all of them. The first problem we faced? By separating them we have lengthened the distance and with it the resistance of the wiring, ergo the energy consumption has risen as a result.
Interconnect implementations

This at certain levels of consumption is not a problem, but in a GPU it is and suddenly we find that we cannot create a graphics processor composed of chiplets using traditional communication methods. Hence the development of vertical intercommunications to communicate the different chips, which means that they have to be wired vertically with a common intercom base that we call Interposer.
Multi-chip designs exist when it is necessary to reach a level of complexity where the size of a single chip is counterproductive in terms of manufacturing and cost, but here the vertical interconnections are generally produced between the different elements above the interposer with it. But it is not as efficient as a direct interconnection, because also a relative intercommunication distance.

On the other hand, when we talk about an implementation with a small-scale chip, we end up opting for what is to stack two or more chips one on top of the other and intercommunicate them vertically. These can be two memories, two processors, or the combination of memory and processor. Of this we already have several cases in the current hardware, such as the HBM memory or the 3D-NAND Flash, the already withdrawn Lakefield from Intel and the Zen 3 cores with V-Cache from AMD.
So the 3DIC is not science fiction, it is something that we have had for several years in the hardware world and consists of creating integrated circuits in which the interaction between the components is done vertically instead of horizontally. Which brings with it the advantages that we have mentioned before about vertical interconnections in the face of energy consumption.



