In the first personal computers, RAM was much faster in speed than CPUs, a well-known case is that of the MOS 6502 in which memory accesses were shared with their video system, but with the passage of time. Over time, the situation was reversed to the point where the main memory of the system became a bottleneck for performance, forcing the implementation of the cache memory in order to alleviate this problem.
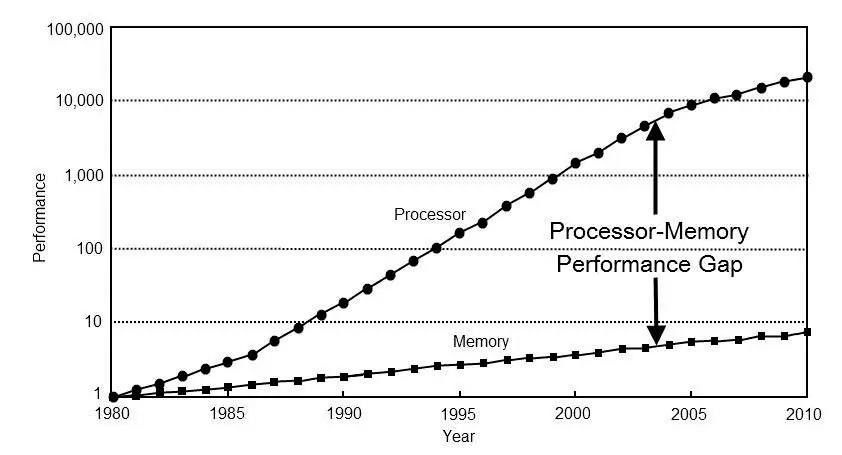
If we look at any graph of the evolution of RAM and CPUs in terms of performance we will see that the distance between the processors and the memory has been increasing over time and is increasing. The questions are, is there an explanation for this phenomenon and a solution?
The reason for the bottleneck between CPU and RAM
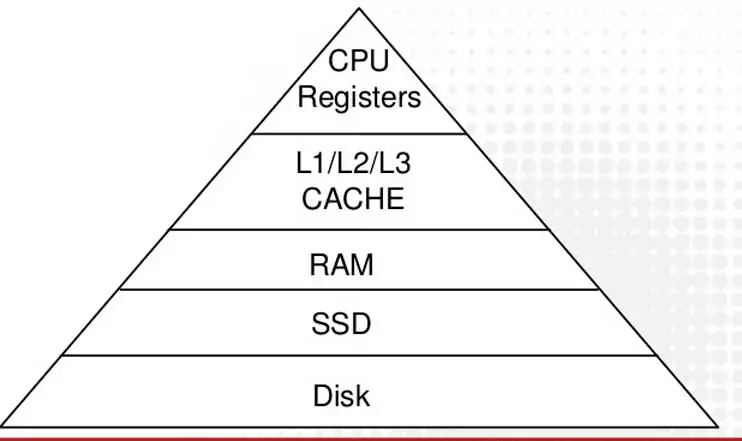
The pyramid of the memory hierarchy is clear, the memory elements closest to the execution units give better performance than the distant ones, in other words, if a data is in one of these first levels of the hierarchy then it is it will resolve in fewer clock cycles.
On the other hand, the further away you are from them, the performance will decrease due to the greater distance that the wiring has to travel. It is at that point where we notice that the random access memory is not inside the processor, which is the main reason for the bottleneck between the CPU and the RAM.
The distance between the CPU and RAM may seem small to our eyes, but in view of the processor it is very high, so the only way to compensate would be to make the memory go at speeds much higher than the processor. It should be taken into account that when the CPU makes a request for access to the memory, a window of opportunity for data transfer opens. The key would be to reduce the communication time between both elements. Which on paper seems easy, however, it is not at all.
Increasing the number of pins is a poor economical solution, as it does not reduce the wiring distance between the two parts and would make the processor and memory larger. What’s more, the only advantage would be to be able to reduce consumption for the same bandwidth, but not latencies.
Why can’t the speed of the RAM be increased?

Transmitting information over long distances causes a problem in that the wiring adds resistance as the distance increases. It is for this reason that transmitting information from caches has a high consumption with RAM. To count what the data transfer consumes we use Joules per bit, or Joules in English, and since these per second are equivalent to watts we can know the energy that is consumed.
Now, increasing the clock speed of the RAM is the other problem, in every semiconductor with a clock signal the consumption is the clock speed times the capacitance and the voltage squared. Capacitance is a constant that depends on the manufacturing node, instead the voltage increases linearly with the clock speed (until it hits the tension walls). The end result is that increasing the clock speed would increase the power consumption of the RAM to stratospheric levels, causing the temperature to rise to the stratosphere and the memory to stop working.
Recently, new methods such as 3DIC have appeared that allow the RAM to be interconnected closely to the processor, in these cases the low latency is due to the proximity and it is not necessary to increase the clock speed. What’s more, they rely on a large number of interconnects to maintain a low clock cycle rate, so that the interface does not overheat and does not cause thermal choking with the processor. This eliminates bottlenecks in this regard, but creates other bottlenecks such as capacity or cost, something that will be alleviated in the future.