Well, it’s really a highly debated topic, because there are many false myths about what a processor can or cannot do and how it can do it with the VRAM of the graphics card. We are going to try to clear the myths once and for all so that we understand the limits of both.
The processor and the VRAM, love/hate relationship?
The first thing we must be clear about are terms such as access and training. The CPU has very limited access to the VRAM, simply to assign lots of memory and locations as such, but within this concept of access it is necessary to qualify a bit.
The CPU and its PCIe controller as well as the VRAM are not directly connected as is the case with the GPU. The PCIe bus needs to be accessed via the GPU driver, BIOS/Firmware which in turn handles the graphic API (DX12 in this case) and from there you get limited access to the VRAM as we say, by block allocation. The problem comes through the allocation of buffers for the vertices, or VB, since these have to be decided by the graphical API where the information has to go and how it is accessed.

To do this, vertex or VAF attributes are used, which, as a general rule, are not implemented well in most games, since the CPU works the addresses and information for the GPU, passes through the caches and from there they go to the system RAMwhich sends the instructions for loading DRAWs on the PCIe bus from the DDR and curiously from there they go to the GPU cache.
This saves a previous step, but as we can see we skipped the VRAM completely, so the programmers and Microsoft, along with NVIDIA and AMD saw that there was a much more optimal way to link the VRAM and the CPU.
PCI-SIG ReBar and VRAM
As we surely know, access to the VRAM was done until the implementation of the two companies in blocks of 256 MB segmented, but these had to go through the structure we talked about before. The funny thing is that it wasn’t necessary because PCI-SIG already had ReBar in their ranks from PCIe 2.0 as such, so they were both late with this limitation.
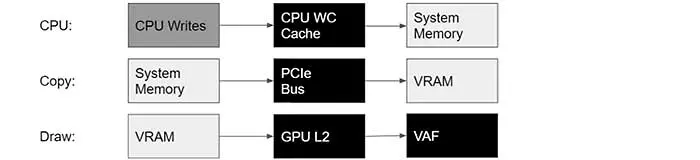 Resizable Bar and Smart Access Memory removed the problem by adding a copy job of the information that is assigned to a sub corethat is, to a processor thread (as a general rule, it is parallelizable, but it affects its performance).
Resizable Bar and Smart Access Memory removed the problem by adding a copy job of the information that is assigned to a sub corethat is, to a processor thread (as a general rule, it is parallelizable, but it affects its performance).
Therefore, the road now went two ways. In one the CPU writes the information in the RAM after being worked by the cache, while in the other hand there is a copy that is sent through the PCIe to VRAM and then from there it goes to the cache to end up in the VAF as such.
What do we get with it? That the CPU directly write a copy of the information in the VRAM and that it be worked by the graphics card cache, for when it is necessary and deemed appropriate through the API information is accessed from RAMwhich already has it assigned before the call, the textures are downloaded to the VRAM (RAMDisk) and from there they go to the GPU after the previous work of its cache, which reduces the total access time and increases performance by general norm.

Ultimately, the CPU can access the VRAM, yes, but only to send you a copy of the information which works so that this saves rendering time and bus offloading, as well as pointless back and forth between CPU and GPU, of course all thanks to GART and DMA drives.
What also has to be made clear is that the CPU “does not see” the VRAM as a memory unit as such. What you see is a device (GPU) connected to the PCIe bus and that it has a type of memory assigned to it, as simple as that. It is the API and the driver that are in charge (after loading the firmware) of working in one direction or another, because as we say, the developer also has to have an engine that can carry out these loads and copies. Because of this, the CPU and VRAM will work one way or another, with one method or another.