There has been for years a ecosystem of applications and tools around CUDA focused on the world of science and engineering and on different branches of each. From medicine to car design. This allowed NVIDIA to grow beyond PC gaming hardware and expand its potential market share.
CUDA is rather is a philosophy for programming algorithms to run on an NVIDIA GPU, although there are also possibilities to do it on a central processor and even on a competitor’s chip. Currently there are several programming languages that have the corresponding CUDA extensions. These include: C, C++, Fortran, Python and MATLAB.
What are CUDA kernels?
In the hardware world we use the word core as a synonym for a processor and this is where the term CUDA kernels conflicts with general lore. Imagine for a moment that a car engine manufacturer sells you a 16-valve engine and marks it as “16 engines”. Well, NVIDIA calls the units responsible for performing mathematical calculations cores, what in every processor are called arithmetic logic units or ALU in English is what the CUDA cores are in an NVIDIA GPU. Specifically, units with the ability to operate with 32-bit precision floating point numbers are usually counted.
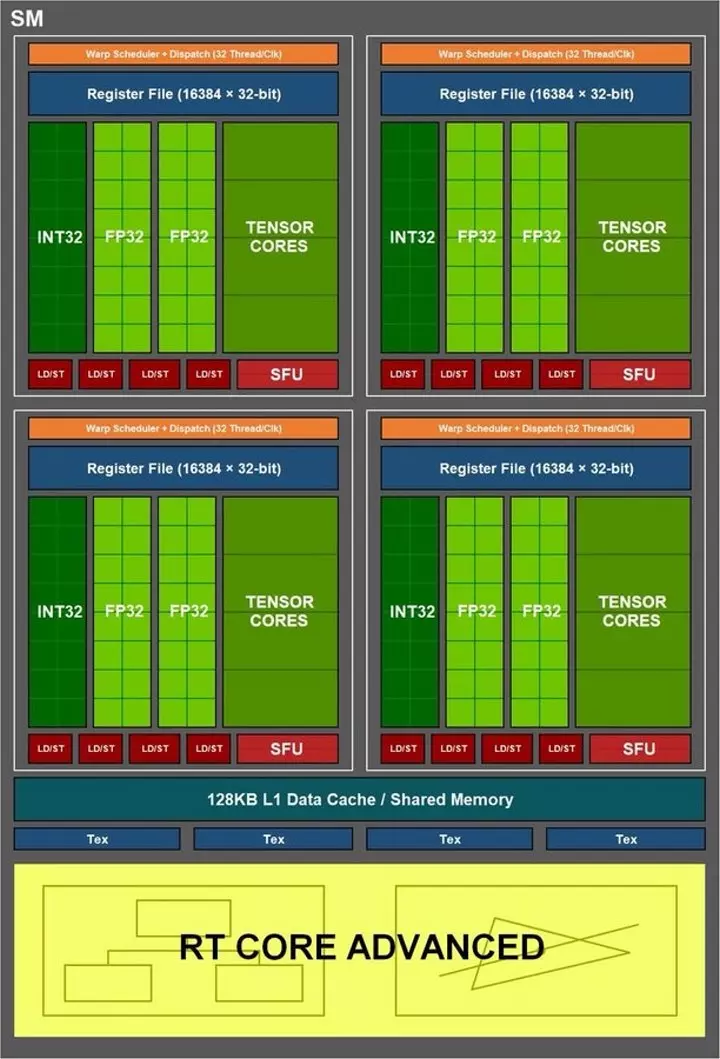
In the case of NVIDIA cards, what is the real equivalent to a core or processor are called SM. So for example, an RTX 3090 Ti despite having 10,752 CUDA cores actually has 84 real cores, since that is the number of real SM. Think that a processor must be able to execute the entire instruction cycle by itself and not a single part, as is the case with the so-called “CUDA cores”.
NVIDIA CUDA versus AMD Stream Processors, how are they different?
Not at all, since AMD cannot use the CUDA trademark as it is owned by its rival, it uses the Stream Processors trademark. Whose use is also incorrect and fair for the same reasons.

By the way, a Stream Processor or Flow Processor in its correct definition is any processor that depends directly on the bandwidth of its associated RAM memory and not on latency. So, a graphics chip or GPU is, but a CPU that is more dependent on latency is not. On the other hand, since NVIDIA and AMD chips understand different binaries it is impossible to run a CUDA program on a non-NVIDIA GPU.
| NVIDIA CUDA Cores | AMD Stream Processors | |
|---|---|---|
| What are they? | ALU units | ALU units |
| Where are they? | On NVIDIA GPUs | On AMD GPUs |
| Can they run CUDA programs? | Yes | Nope |
Are there different types of NVIDIA CUDA Cores?
We usually call 32-bit precision floating point units as CUDA kernels, but other types of units are also included within the definition, which are:
- ALU units with the ability to work with double precision floating point numbers, that is, 64 bits.
- 32-bit integer units.
Because GPUs do not use a system of parallelism with respect to instructions, what is done is to use concurrent execution. Where a unit of one type can replace another type in the execution of an instruction. This is an ability that NVIDIA chips have from the Volta architecture onwards, in the case of desktop systems, from the RTX 20.
Instead, THEY ARE NOT CUDA CORESthe following SM drives on the GPU:
- Tensor Cores, which are responsible for executing operations with matrices. In general purpose they are used for AI and in graphics they have utilities such as DLSS to increase the resolution automatically.
- RT Cores, which calculate the intersections of the rays throughout the scene during Ray Tracing.
- SFUs, which have the ability to execute complex mathematical instructions faster than conventional ALUs. Supported instructions include trigonometric operations, square roots, powers, logarithms, and so on.
Which, despite also being arithmetic-logical units, are not counted by NVIDIA as such.
How do CUDA kernels work?
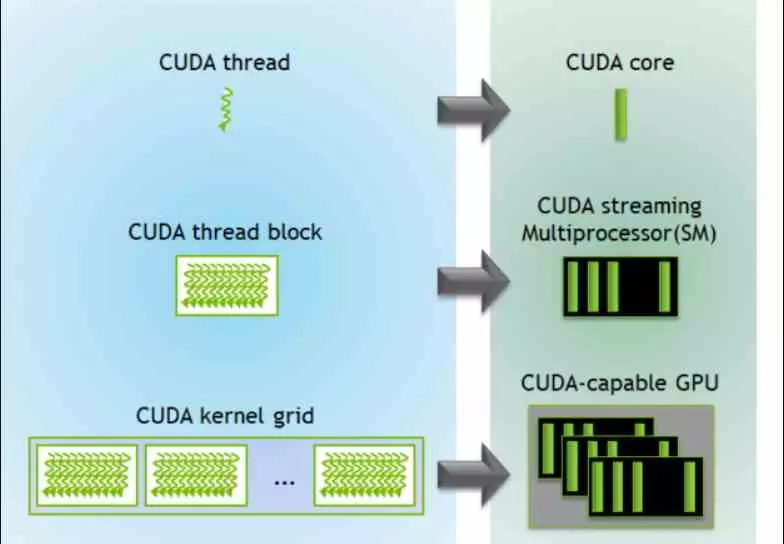
In general terms, CUDA cores work in the same way as any unit of this type, if we speak more specifically we have to understand what a thread of execution is for a contemporary graphics chip and conceptually separate it from the same concept in a central processor.
In a program executed on a CPU, a thread of execution is a program with a series of instructions that perform a specific task. On the other hand, in a GPU each data has its own thread of execution. This means that each vertex, polygon, particle, pixel, chunk, texel, or any other graphics primitive has its own thread running on one of the CUDA cores.
How are instructions executed in the CUDA core?
Also, the way to execute the threads, and this is in general on all GPUs, is by using a variant of the Round-Robin algorithm. Which consists of:
- Instructions are categorized into groups based on the number of clock cycles they take to execute from each of the ALUs/Stream Processors/CUDA cores.
- If the instruction in a thread has not been executed in the given time, then it is moved to the queue and the next one in the list is executed. Which does not have to correspond to the same execution thread of the first one.
Keep in mind that complex 3D scenes today are made up of millions of visual elements to form the complex scenes and that they are formed at a fast enough speed. Therefore, the CUDA cores are the basis for processing all these elements in parallel and at great speed.
Their great advantage is that they directly execute the data found in the registers and, therefore, in the internal memory of each SM. Therefore, they do not contain instructions for direct access to VRAM. Rather, the entire ecosystem is designed so that threads are pushed from memory to each of the GPU cores. This prevents bottlenecks in memory access. This implies a change with respect to the traditional model of memory access. Other than that each of the SM where the CUDA cores are located are much simpler in many functions than a CPU core.
CUDA kernels cannot run conventional programs
The execution threads that will execute the CUDA kernels are created and managed by the central processor of the system and are created in groups by the API when sending the lists of graphic or computational commands. When the graphics chip’s command processor reads the command lists, they are classified into blocks that are each distributed to a different SM or real core. From there, the internal scheduler breaks down the execution threads according to the type of instruction and groups them to be executed.
This means that they cannot execute conventional programs, due to this particular way of working of the cores in the GPUs of the graphics cards, since their nature prevents them from doing so. That is why you cannot install any operating system or run any conventional program on them.