It must be taken into account that NVIDIA began to differentiate its graphics cards for servers from those used in the home and professional markets starting with the GP100, whose architecture was different from its contemporaries for gaming, the GTX 1000. Since then the differences between both ranges they have been increasing more and more. The main one being the fact that the shader unit, known as SM in both ranges, completely differs in focusing on different needs. One to reproduce the graphics of PC games and the other for scientific calculations.
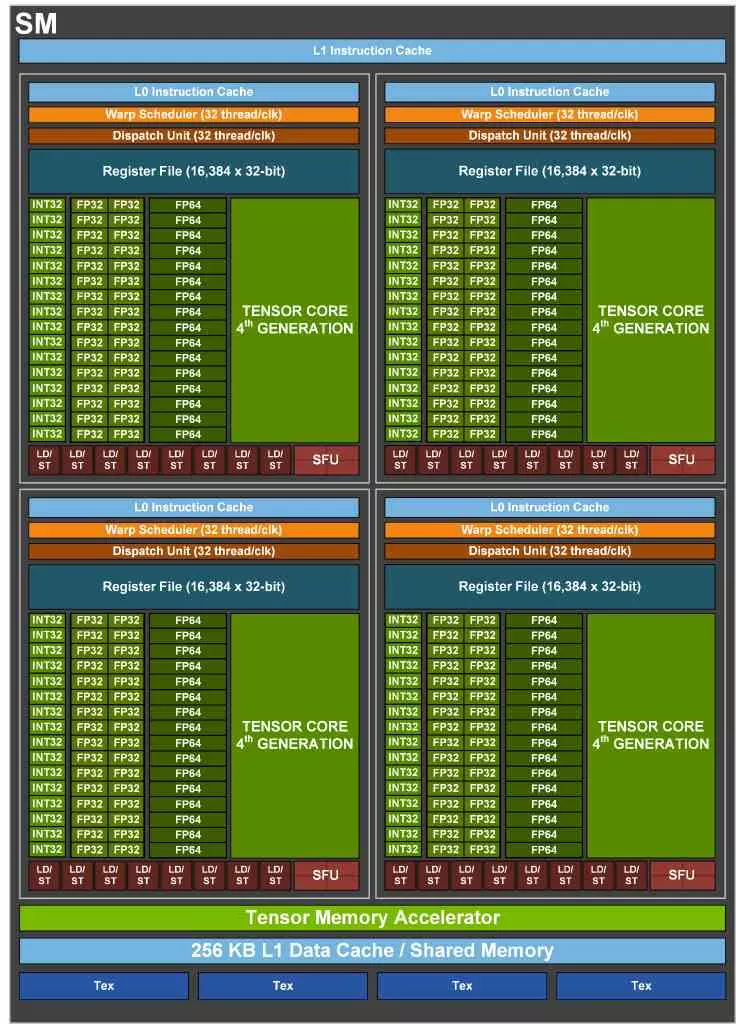
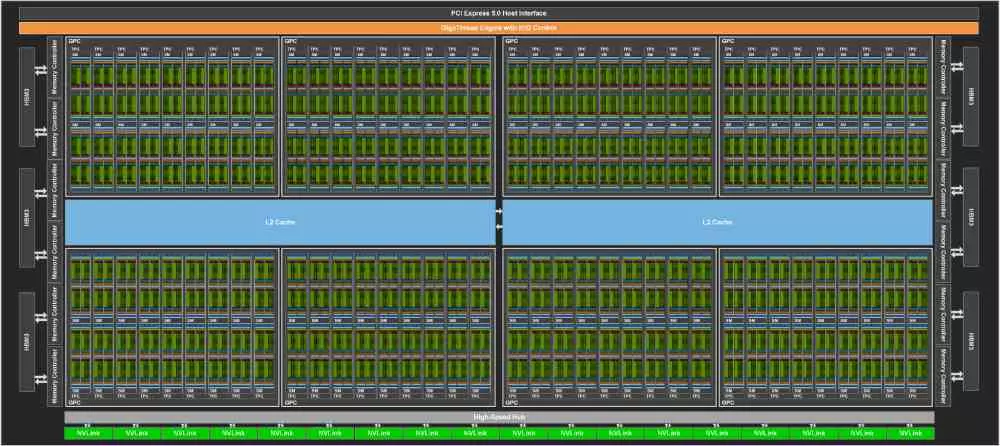
How can you see the RT Cores to accelerate Ray Tracing are not found in this graphics card, hence it does not receive the name of RTX. Instead, we have that GPUs like the NVIDIA GH100 support double-precision floating point. Which is essential for work in certain fields of scientific and engineering research. We also have to keep in mind that despite its name, the NVIDIA GH100 Tensor GPU cannot render graphics with the same speed and smoothness as gaming cards.
This is the NVIDIA GH100 Tensor GPU, a beast for AI and Deep Learning
For the manufacture of this mastodon of more than 800 mmtwo, although somewhat smaller than its predecessor, NVIDIA has opted for the N4 node, a somewhat more optimized version of its 5nm node. On which he has created a design that in a certain way is continuous with the same type of processor of the previous generation, the A100. By the way, we cannot forget that we have two versions, one with the SXM form factor for supercomputers and another in the form of a PCI Express card, which by the way does not use the new PCIe Gen 5 connector and is limited to 350 W. Instead, the full version can reach 700 W of consumption in total.
As for its official technical specifications, for the different models they are the following:

As you can see, apart from adopting the configuration regarding the 32-bit floating point units of the RTX 30, with the second array of them switched with the integer unit, what stands out the most is the HBM3 memory usage for the first time on finished hardware. Although at the moment we do not know if the first models are going to use HBM2E memory while NVIDIA waits for the new standard to be widely available. Regardless of the type of memory used,
What changes from the NVIDIA GH100 could we see in the RTX 40?
The most obvious of all are the Fourth Generation Tensor Cores which are now much wider and can exceed the PetaFLOP of power, that is, 1000 TFLOPS. However, as happened with RTX 30 compared to A100, it is most likely that they leave out a good part of the capabilities. Especially all those related to the training and support of certain data formats.

The second point that also draws our attention is the addition of the Tensor Memory Accelerator, which allows Tensor Cores to access data beyond the L1 cache when the L1 cache and registers are busy performing other tasks. In other words, memory access will no longer be switched and this is going to be a huge advantage in Deep Learning algorithms applied to speed up and visually improve games.


Now to finish our quick summary, another of the novelties that we will see in the RTX 40 and that have been released with the NVIDIA GH100 Tensor GPU has to do with the intercommunication between the SM. the calls Thread Cluster Block that allow a set of SMs to directly intercommunicate without them having to go down to look for the data in the L2 cache or, worse, in the RAM of the card itself. Thus reducing the latency in the intercommunication between the different cores that make up the chip.