The 2022 GTC is off to a great start. NVIDIA has made very important announcements, confirming once again that it is at the forefront of the industry. In this sense, one of the most important novelties has been Hopper, the new GPU architecture that uses its NVIDIA H100 accelerator, an extremely powerful solution that adds a total of 80,000 million transistors, and that offers a power of up to 1,000 TFLOPs in FP32which is a 300% increase over the NVIDIA A100.
During the last weeks we had seen numerous rumors that Hopper was going to be NVIDIA’s first modular architecture, but we also saw others that pointed in the opposite direction, and in the end these have been the ones that have been fulfilled. The NVIDIA H100 uses a monolithic core GPU that integrates a total of 132 SM drives in its SXM5 form factor, and 114 SM drives in its PCIE Gen5 version. This leaves us with a count, respectively, of 16,896 shaders and 14,592 shaders. Both versions add 528 and 456 tensor cores, specialized in artificial intelligence, inference and deep learning.
Hopper is made in the TSMC’s 4nm nodewhich makes it not only the most powerful GPU that exists so far, but also the most advanced due to the manufacturing process it uses.
TSMC’s leap to 4nm has been key for NVIDIA to be able to triple the raw power of the NVIDIA A100, but without even doubling the consumption. And speaking of consumption, the PCIE Gen5 version of the NVIDIA H100 has a TBP of 350 watts, while the SXM5 version can reach 700 watts.

NVIDIA H100: The most powerful and advanced GPU that exists
By offering two different formats, NVIDIA is able to meet the needs of different businesses and reach a larger number of professionals, which is obviously a good thing. The rest of the NVIDIA H100 specs are rounded out with up to 50 MB of L2 cache, a 5,120-bit bus, and up to 80 GB of HBM3 memory. In total, it is capable of achieving a bandwidth of 3 TB/s, 150% more than the NVIDIA A100, and is compatible with the latest technologies and solutions in the industry.

NVIDIA also took advantage of Hopper’s presentation to talk about the dynamic programming algorithmswhich are based on two main keys: recursion, which breaks down a large problem into several small problems to facilitate its resolution, and memorization, which stores answers and solutions that can be used again to solve other problems.
These algorithms are used in numerous sectors such as health care, robotics, quantum computing, and scientific research, among others. According to the green giant, the Hopper architecture is able to offer a performance improvement in a factor of 40x (forty times) thanks to the use of new DPX instructions.
Sounds good, but what will this mean for professionals? Well, very simple, the new DPX instructions allow developers to write code capable of accelerating dynamic programming algorithms in multiple industries, which will translate into a significant boost in workflows in such important fields as disease diagnosis, quantum simulation, graph analysis and routing-level optimizations, something key in robotics.

With NVIDIA Hopper (H100), DPX Instructions Can Accelerate Dynamic Programming Algorithms up to 7 times more than with an NVIDIA Ampere (A100). Obviously this scales proportionally, which means that with an NVIDIA H100 multi-accelerator node the jump in performance ends up being huge. We must not forget that, in addition, Hopper uses the new fourth generation tensor cores, specialized in AI, inference and deep learning.
NVIDIA Grace: A super CPU for data centers

Another of the most important “novelties” (in quotes because we already “knew each other”) that NVIDIA announced at GTC 2022 has been Grace, a super CPU aimed at the professional sector that uses the ARM architecture, and is made up of two processors joined on a PCB and interconnected to work as if they were a single chip. This solution represents one of the most important bets of NVIDIA in its race to lead the data center sector, and will be available in two different configurations.
In total, NVIDIA Grace adds 144 ARM v9 cores, a spectacular figure that guarantees high multithreading performance. As expected, NVIDIA has accompanied Grace with LPDDR5X memory to maximize performance, it has confirmed a bandwidth of 1 TB/s and the integration of ECC technology (bug fixes), a very important detail as it means that NVIDIA Grace is ready to integrate seamlessly into any scientific research environment, even those where complex simulations that require total precision are performed.
NVIDIA Grace uses a new fourth-generation NVLink-C2C coherence interface, which achieves 900GB/sit is estimated that it could reach a score of more than 740 in SPECrate 2017_int_base, double the performance per watt of any current top-of-the-line processor and is also compatible with all of the green giant’s software stacks and platforms, including NVIDIA RTX, HPC, NVIDIA AI, and NVIDIA Omniverse. Grace will be available both as a stand-alone and in another with Hopper, but it won’t arrive until the first half of 2023.
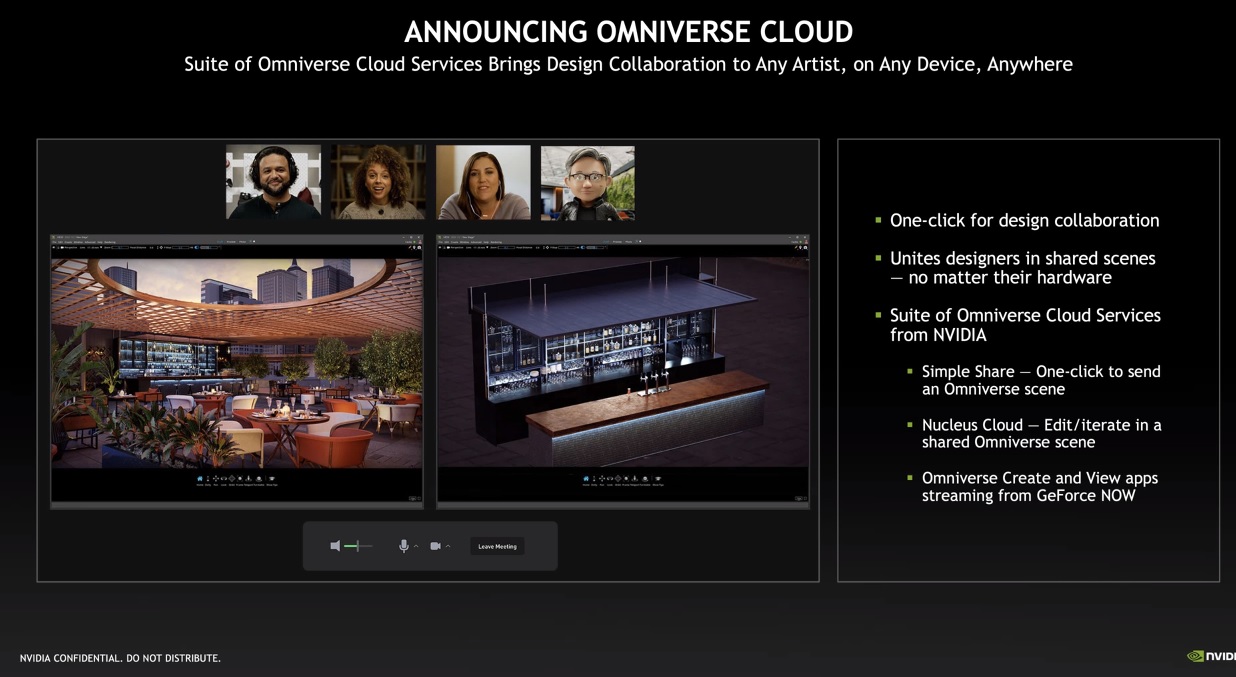
Other important news
The GTC 2022 has given much, that is undeniable. NVIDIA has introduced a lot of newsamong which we can highlight the Omniverse Cloud for developers, which we have already told you about in this article, Omniverse Avatar, NVIDIA Spectrum-4, NVIDIA OVX and the NVIDIA OVX SuperPod.
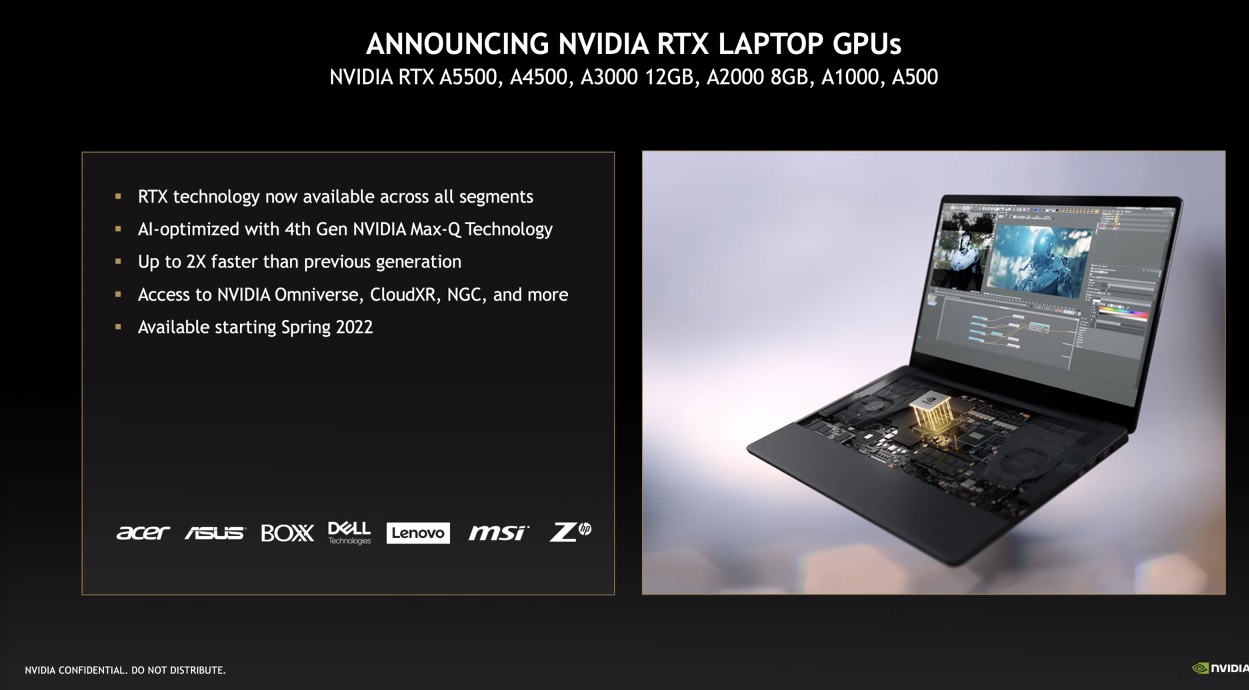
In MuyComputer we have also talked about the new RTX A5500 for professionals, and new professional solutions for notebooks based on the fourth generation Max-Q technology, which will be used by the main players in the notebook sector, including giants such as Acer, ASUS, Dell, Lenovo, MSI and HP.


We cannot finish without talking about the NVIDIA DGX Station H100, a supercomputer that is emerging as the fastest solution of its kind working with AI. It is made up of 8 H100 graphics accelerators, reaches a peak performance of 32 PETAFLOPs in artificial intelligence workloads and adds up to 640 GB of HBM3 memory, whose bandwidth is 24 TB/s. This is also the “basic unit” of the nvidia eos, a super computer that integrates a whopping 576 DGX Station H100 blocks, which translates into 4,608 H100 GPUs.