It is very clear that a CPU cannot do the work by itself, there are common operations that a computer carries continuously in which a general-purpose processor is not efficient, but first of all we should understand what this means and why they are necessary. support chips.
When designing a new architecture there are a series of parameters that mark the limits that engineers should not exceed, including things like the type of libraries used for the design, how much the chip will consume, what will it be? its size, but especially what common problems it is seeking to solve with the new processor. It is at that point where not only the main units are defined, but also the coprocessors and accelerators that will be part of it.
The first support processors that are placed in an architecture are easy to elucidate, usually those that have been designed for previous architectures of the same brand or, failing that, those that have been licensed to third parties. The latter, on the other hand, are born during development, as a result of customer requests or due to the type of problem to be solved that requires a new type of hardware unit.
What is a coprocessor?

Although the signifier is self explanatory, it is important to bear in mind that if we have several nuclei working together to solve the same problem common to distributed parts, then we are talking about each of the process units acting in co-processing with others. . And yes, we know that it has crossed your mind, but when we have several cores of a CPU tackling a specific problem, we are talking about those that do not execute the main process are acting as co-processors of others.
Supporting chips have traditionally been called coprocessors, although the most famous coprocessor in the history of the PC is the mathematical coprocessor, which was nothing more than what would later become the floating point unit or FPU that was totally decoupled from the main CPU. Thus, the coprocessor generally lacks a process for capturing instructions from memory, but needs another processor to send the instructions and data to be processed. The work of the coprocessor? Solve that part of the program and return the result as quickly as possible to the host processor.
During the time that the coprocessor is in charge of doing its work, the main kernel can use the power it has gained to carry out other tasks, but since a process is being executed together, the point will be reached where it will not be able to continue until the coprocessor or coprocessors have completed the task assigned to them.
What is an accelerator?
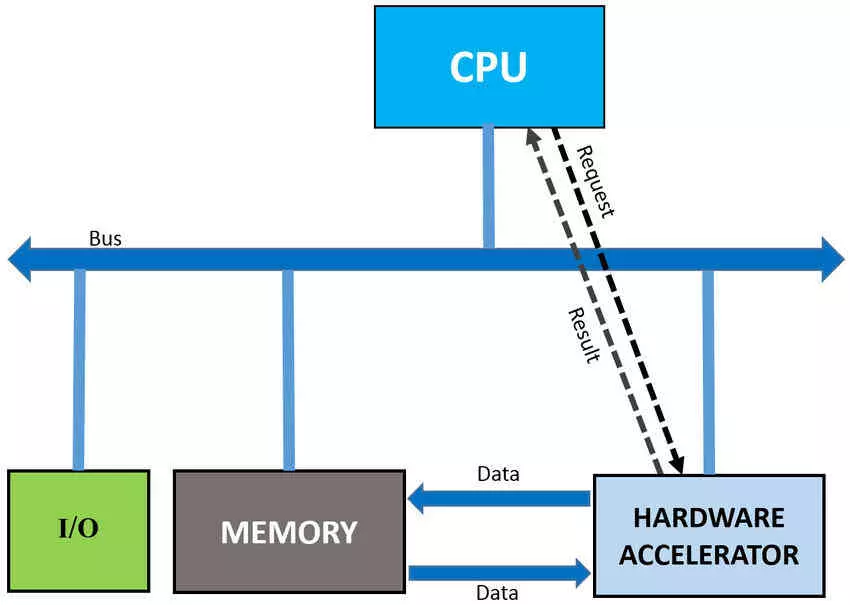
Technically, an accelerator is a coprocessor, but with greater independence than these since they are not in charge of executing a process as a whole, but rather they are assigned an entire process that the CPU completely ignores except to obtain the final result or to know that the task has been completed.
Because an accelerator is completely decoupled from the processor, it is totally asynchronous to it. What do we mean? The fact that an accelerator as opposed to a coprocessor does not work in combination with the main CPU of the system. This allows you to speed up your part of the code, which means completing it at a much higher speed and therefore in less time. Of course, this requires major changes in the architecture.
First of all, a coprocessor can share parts of the control unit and even registers or access to a common memory with the CPU. When all these elements are shared, they can create congestion in the access to them, causing one unit or another to be stopped waiting to use these resources. As you will understand, this cannot happen in an accelerator, so its data and instructions, despite being provided by the processor, are designed to be available to you 100% of the time, that is why many accelerators are complete processors that have their own Local RAM inside.
If an accelerator is better, why is a coprocessor used?

We have said it during the introduction of this article, everything has to do with the budget that architects have when implementing the solution to a problem and one thing that is usually not taken into account is the communication infrastructures between the different elements , as well as the units that are part of the instruction cycle of each processor, but that are not responsible for crunching numbers at high speed.
At the marketing level, it is very easy to sell the power of a processor in numbers, these are easily understood by people who can make an ordinal or cardinal comparison from said data. The reality is that nowadays the infrastructures in any processor are what occupy the most space and that is why the decision to implement something in the form of a coprocessor or accelerator is just taken due to these limitations.
An example is the Tensor Cores and NVIDIA’s NVDLA unit, both serve the same purpose, but while the former are a coprocessor within the shader unit that shares registers and control unit with the rest of the GPU shader unit, in the case of the second is a processor itself. Not surprisingly, the acronym DLA stands for Deep Learning Accelerator.