
The Zen 4c architecture represents a very important advance on the part of AMD and is a clear reflection of the versatility that the chiplet offers. As we told you a few days ago when the new AMD EPYC 97X4 was officially presented, the Sunnyvale company has been able to evolve the original design of Zen 4, based on 8 cores and 32 MB of L3 cache, and make it one that integrates 16 cores and 16 MB of L3 cache.
Quite an achievement, without a doubt, but it is also a reflection of something very important that is becoming more and more of a problem, and that has been precisely what has made the development and interconnection of heterogeneous chiplets become one of the central pillars within the technology sector, space at the silicon level and the great impact that some parts have within it.

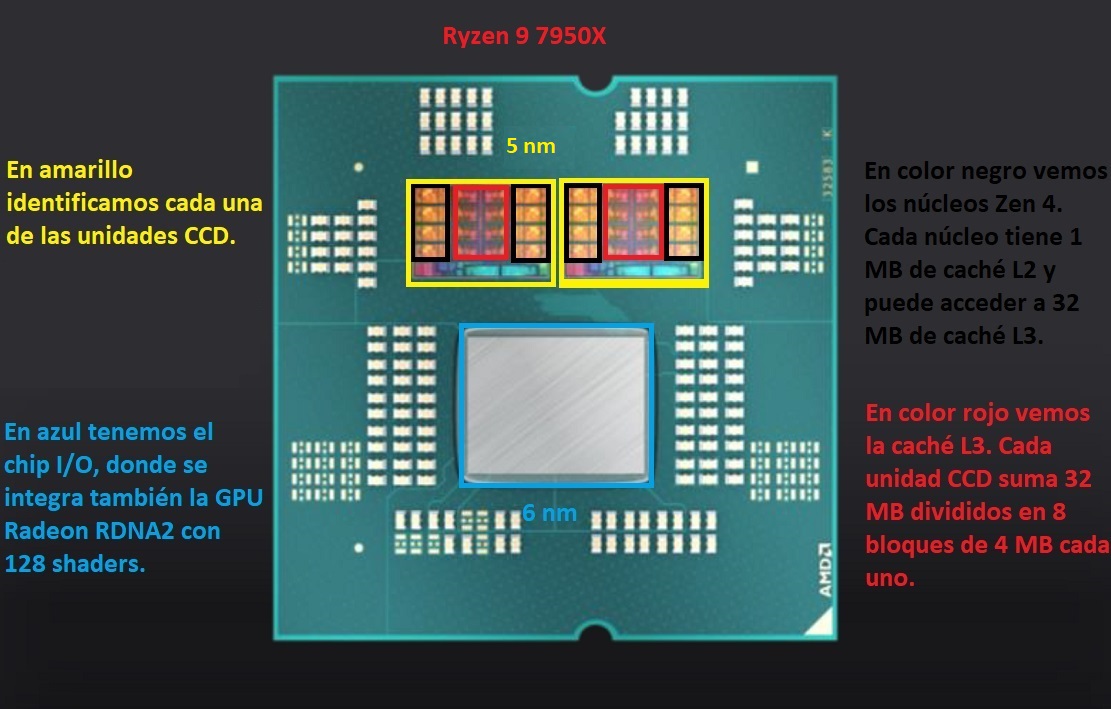
In this sense, we see that AMD had to reduce the L3 cache by 16 MB to free up a huge amount of space. This space has been key to being able to double the number of cores, something that is undoubtedly impressive and that shows the enormous amount of space that the L3 cache occupies inside a silicon chip. This reality was also what forced AMD to outsource the L3 cache on its Navi 31 and Navi 32 GPUs.

If you look at the attached image you will see better the large amount of space that the L3 cache occupies in processors based on Zen 2 and Zen 3, and the same happens with processors based on Zen 4 architecture, as you can see in the image lower. The 32 MB of L3 cache takes up almost the same space as the 8 x86 cores, so halving it frees up a lot of space on the chiplet.
AMD too has reduced the size per core in the Zen 4c architecture, which goes from 3.84 mm2 to 2.48 mm2, another movement that has been essential for the American company to become the first to present a high-performance x86 processor with 128 cores and 256 threads .
It will be interesting to see how this new architecture evolves in future generations, but seeing how badly the cache is scaling With the more advanced nodes, the space it occupies and the impact it can have on certain tasks, I think that in the end it will progress more and more designs with 3D stacked cache or outsourced to interconnected chiplets.



