
They haven’t been specified as such, but there are some rumors that Link Tiles could go to 5nm under TSMC, GPU dies on N4 and caches and other parts like Passive Die Stiffeners with Intel 4.
But, on the other hand, the slides shown eliminate one of the factors discussed a moment ago, since they curiously do not show Intel’s RAMBO Cache. This could indicate that Intel is going to include it within the GPU Tiles and thereby create more complex chips that could arrive with its manufacturing node. Intel 4 and thus leave aside TSMC in this part of the game.
The fact of using memory is also rumored HBM3which would give a higher bandwidth and forces Intel to update its architecture Xe Link. It must be understood that any accelerating GPU of this type has memory bandwidth as its main limitation, performance is proportional to it, so that is why Intel announces more FLOPS and GT/s without giving further explanation.
That said, let’s jump to other equally important tasks with Rialto Bridge.
OAM 2.0, the consumption and increase of Cores
The type of socket that Intel will use for Rialto Brigde will be OAM 2.0which is a surprise since we did not know anything about it and also, according to what has been said, it is going to be a brutal figure in terms of capacities and consumption, since we went from 700 watts with its first version to nothing less than 800 watts in this second.
This increase is really designed to achieve more efficiency, since if we take into account that Ponte Vecchio includes 128 EUs, Rialto Brigde goes to the 160 Cores Xe to his credit, an increase of 25%, which, given the increase of 100 watts, actually affects greater efficiency.
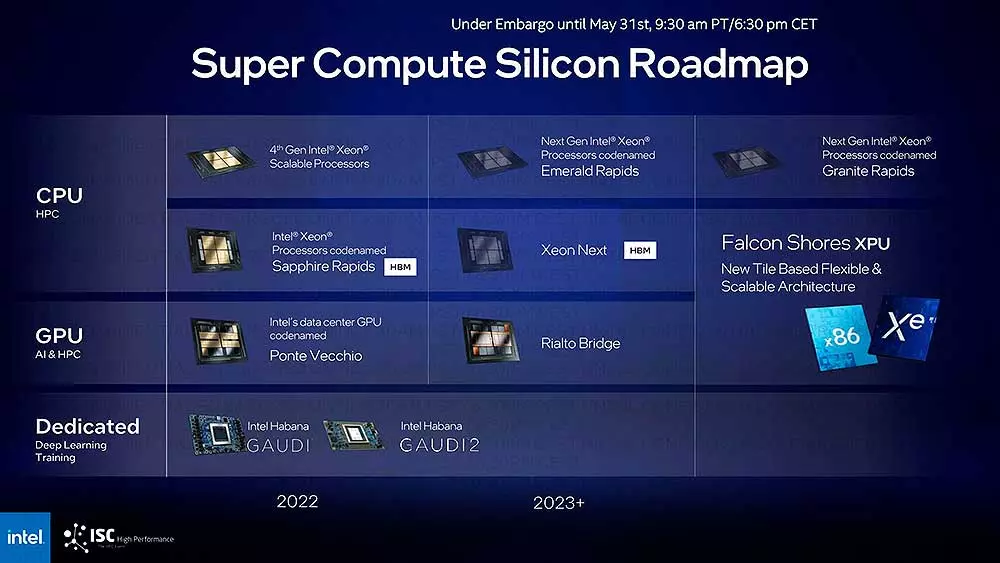
As for performance itself, Intel ensures that we will see it take off a 30%which is not impressive given the figures that we have exposed for Cores, but it is a leap forward in general terms in the absence of seeing the final frequencies.
Finally, and before talking about the future as such of this technology, Intel has set the date of Sampling 2023 for Rialto Bridge without specifying any quarter, figures very similar to those of NVIDIA with H100 and its Grace servers, where here those of Huang they have some advantage. And it is that Intel’s objective is clear if we look at the roadmap that it has provided: 2023 will be the year where the new Xeon and Rialto Bridge will arrive and in 2024 or 2025 they will make the leap to Falcon Shoresthe architecture that will unite both in a new concept called XPU.
The future is Falcon Shores, the XPUs that will revolutionize the market
Falcon Shores will be the implementation with Tiles in a flexible and scalable way, a twist to what we have seen with the NVIDIA Grace SUPERCHIP where with EMIB and Foveros 3D Intel makes the leap to a single modular product that through a single socket can have all kinds of products to suit the consumer. From GPUs, CPUs to a mixture of both, this XPU concept will clearly be the dominant one in the industry to the point that we do not rule out the possibility of including some parts of an FPGA.

Intel gives more or less interesting details, since it states that with Falcon Shores the performance per watt will be increased by up to 5 times, the density per x86 socket by 5 times and memory capacity b/w at the same value, a concept that will later be imported to PC in a much simpler and above all cheaper way where luckily we will not have as many changes as such (lower price).
And it is that we start from a very decent CPU and GPU base that will only be enhanced by modular packaging and interconnection technologies, moving Intel directly to MCM architecture as AMD is going to do with Zen 4 and its iGPUs.


