More details: https://t.co/GIkfwrXGzV pic.twitter.com/sXGt9nbJ1S
— Underfox (@Underfox3) February 3, 2022
As we know, so far it’s all been AFR and SFR on both single and multi-die graphics cards, even if these were really SLI and Crossfire in disguise. The future scenario will be similar, but above all it offers the advantage of totally independent chips on the same PCB through an interposer, just as AMD is doing right now with Ryzen, Threadripper and EPYC, but in GPUs.
Intel’s new patent shows precisely how it’s going to make its GPUs work with different cores (dies), since the technologies of AFR and SFR They do not scale at all as they should despite the fact that on paper they are optimal, but in the real world they have too many problems. The idea that Intel has had is quite simple in concept, but really complicated to implement in hardware.
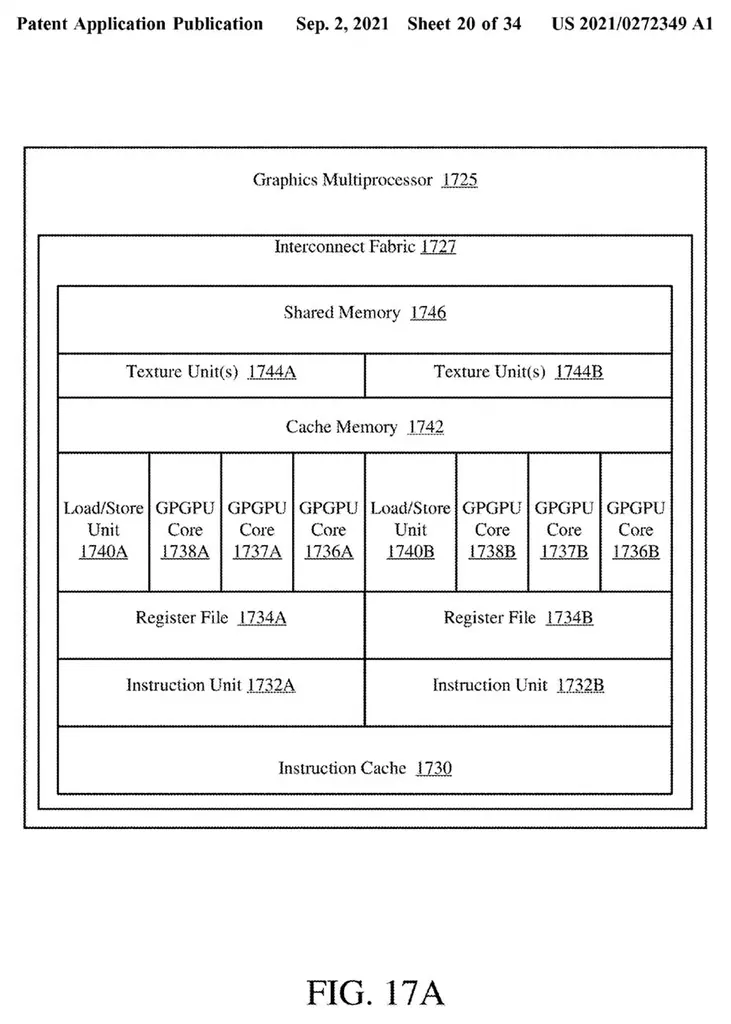
What Pat Gelsinger intends is to include a command buffer where he divides the draw calls and channels them to the corresponding dies through a render checker integrated with Tiled. This division seems to be done randomly, where once the dies that will work on it have been made and selected, they will be executed by a new unit called POSH or Position-Only Shaders.
These units work within the dies and are in charge of sending the Draw to the corresponding nuclei also randomly. Obviously there is an order of workload and especially of representation on the screen, where this will be divided into Tiled through the checker board described above or checker. This allocates and checks that each primitive is present in a space on the screen.
Once the assignment is done and the visibility data is correct, priority is given to the most relevant primitives through the geometry processor and once it has done its job, the pixels are processed so that each core has worked on a part of the tiled depending on its complexity, resulting in optimization of time and calculation.
The benefits of per-core tiling on Intel MCM GPUs
Logically, the rendering engine and the complexity of the assignments make the scalability increase as matrices are added to the equation, that is, even if the system is complex if the rendering engine allows scaling almost 100% the higher the number of dies/cores, then we will not find performance limits as such.
This shows that Intel has the foundations well established and that the future is undoubtedly multiple dies in addition to multiple interposer, where the number of cores will progressively scale and we will no longer talk about Shader as the scaling unit as such, but as one more unit of rendering where the important thing will be its total number based on the cores that the GPU has.
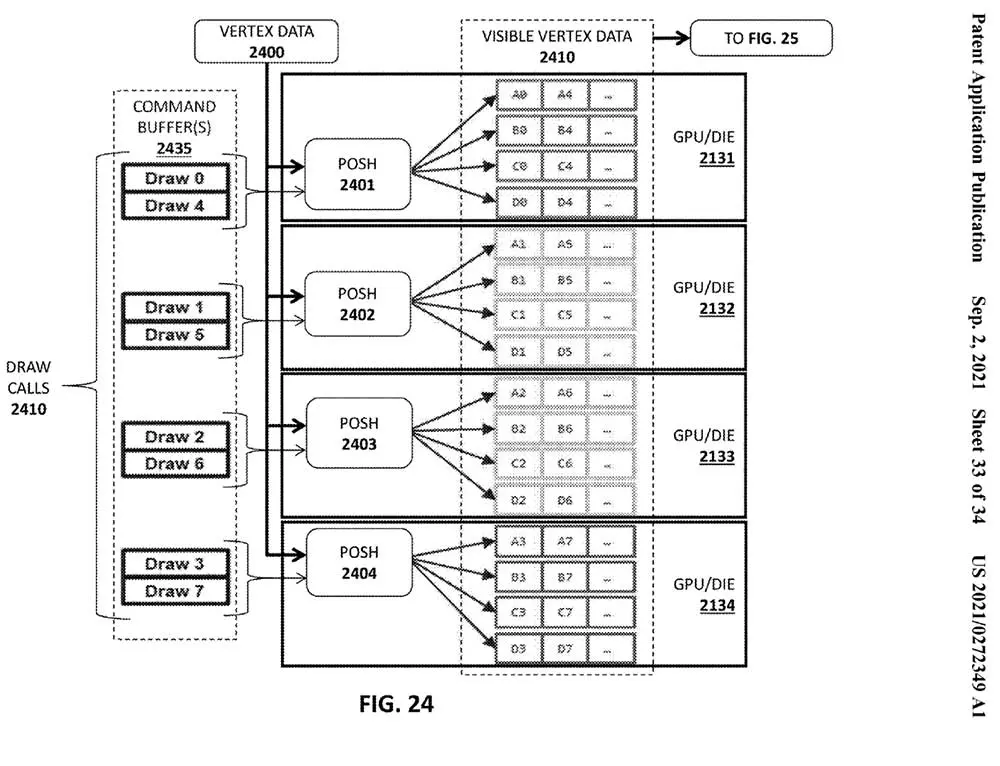
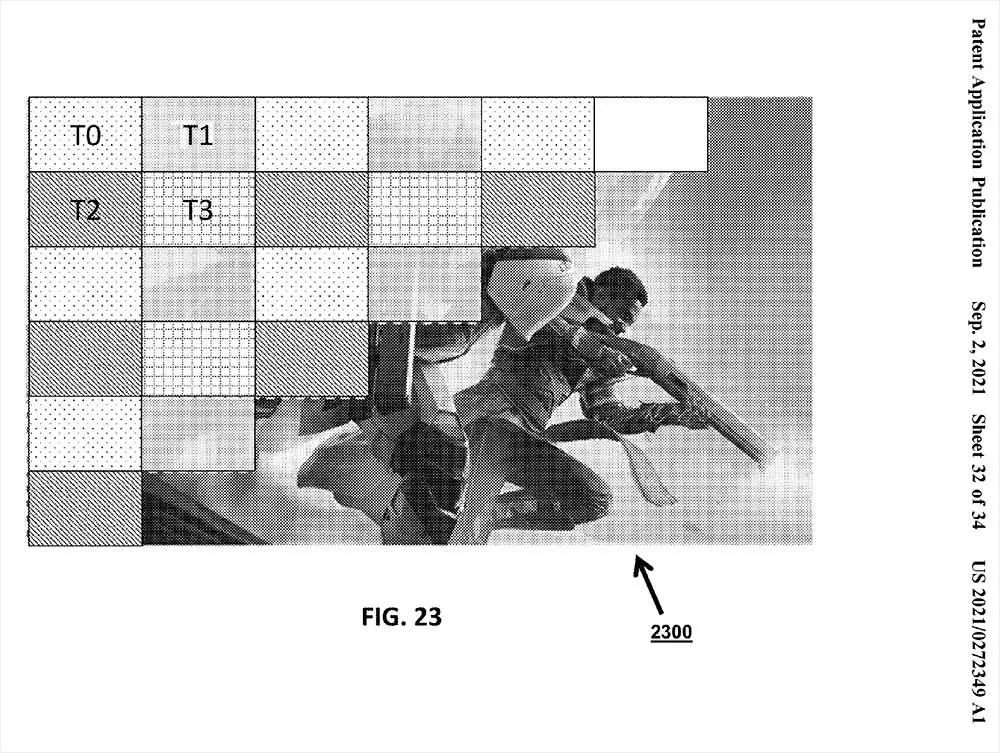
In short, Intel is going to segment the screen, the global image frame by frame in Tiled, where each one of them will be worked by fragments that will be larger or smaller depending on the number of dies that the GPU has and at the same time, the more cores have a die more divisions each Tiled will have, managing to complete a very expensive task in as many shards as the hardware allowsof lower total complexity and providing higher speed per frame.
A risky bet that takes not one, but several steps beyond the Tiled technology that NVIDIA implemented as a rendering mode, all thanks to the approach that Intel will use with MCM in its GPUs.