With the RTX 30 and RX 6000 sold out everywhere it is surprising that the next generation of graphics cards is being talked about. Well, it really isn’t and officially neither AMD nor NVIDIA have said anything about their architectures. But, there are a series of rumors that logically ordered and with knowledge about graphics hardware architectures paint a very interesting scenario for the future.
A battlefield with a common node

Both architectures will face each other by making use of TSMC’s 5 nm node, which in AMD’s case will also be used to manufacture its Zen 4 APUs and CPUs. As for NVIDIA, it is a return to the Taiwanese foundry after that the RTX 30s have been in the making at Samsung.
TSMC, which is aware of this fact, will make its wafers pay for the highest bidder, this will translate into a rise in prices and the space in the TSMC factories must be reserved. The actual situation? AMD doesn’t seem willing to continue being the cheap brand compared to NVIDIA. Which was part of the reason why AMD couldn’t get as big a market share as NVIDIA. Not only because of the worse performance, but because of the fact that the less money earned, the fewer wafers to pay for, and the fewer wafers the fewer graphics cards end up being produced.
The high prices compared to the past in the case of AMD we are already seeing with the RX 6000 and it is a trend in which Lisa Su’s company will continue the price escalation until it matches the level of NVIDIA. After all, the market has accepted the high prices of the last generations of NVIDIA cards and AMD is still a multinational with the desire to make money.
What does NVIDIA have in store for us with Lovelace?
Lovelace is currently a huge unknown, the only data we know does not come from NVIDIA but from Kopite7Kimi, an insider who got the specifications of the current RTX 30 right more than a year in advance. The most outstanding figure? The 18,432 CUDA cores or ALUs in FP32 that the new NVIDIA graphics architecture will supposedly have, a considerable increase that almost increases the number of CUDA cores in the more powerful GA102.
In the RTX 30 we have seen how the average number of ALUs in FP32 per shader unit or SM has gone from 64 to 128, a figure that translates into 144 SM in total, a figure even higher than that of an NVIDIA A100 and results in the Most impressive leap, if that’s true, in any NVIDIA generation. Such a jump makes us partially skeptical of such information.
It is quite possible that the 18,432 CUDA cores are a figure that corresponds to NVIDIA Hopper and not Lovelace. After all, Hopper will be to Lovelace what Volta was to Turing. The reason we think this is because of the rumors of the new organization that is rumored for Hopper and that it will most likely end up being used in Lovelace
A new organization for Hopper and Lovelace
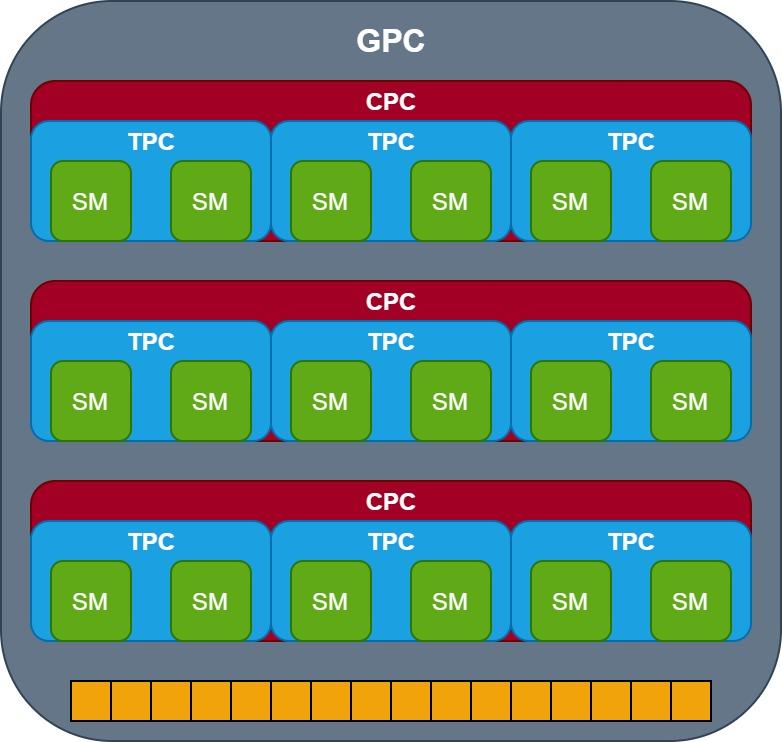
There is another rumor that speaks of change in the organization of your GPUs in the next generation by NVIDIA, where the minimum unit will be the SM and the subcores will disappear, so the SM unit will have a general scheduler instead of having one in each subcore, in that aspect it will look much more like the architecture from AMD where the lowest level cache is shared for all SM equally.
The next point is the TPC, this does not undergo changes, except that this time it will group 3 SM instead of 2 SM, but it is in the appearance of the Cluster Processor Core where the interesting comes from. Each CPC will have 3 TPC inside it and therefore we speak of 18 SMs per GPC or 6 per CPC. The particularity of CPCs? Apparently each one is assigned a new L1 cache of data and instructions. The amount of CPC per GPC? Well, according to rumors, there would be three in total, but the amount of CPC per GPC could be variable as the number of TPC currently is, but we do not know this last detail.
You could be confusing Lovelace with Hopper
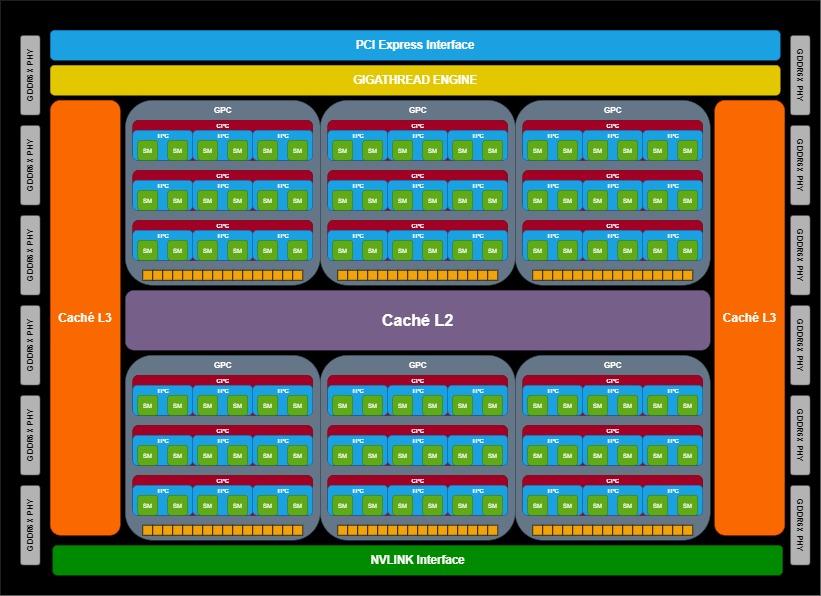
What makes us doubt about the number of SM drives in relation to this rumored new organization is that it takes 8 GPCs to achieve this and the number of GPCs in NVIDIA GPUs has almost always been in line with memory bandwidth. . Where typically 6 GPCs equate to a 384 bit bus and a wider bus is not typically used in commercial GPUs.
There is a possibility that Lovelace was mistaken for Hopper regarding its possible configuration. Once we see more possible and realistic. And for the record, this is speculation on our part based on things we’ve heard. And it is that NVIDIA Lovelace in its most powerful GPU could have a configuration of 6 GPC next generation, which would allow it to reach 108 SM. A figure that, although it would be lower than the rumored 144 SM, is a important jump compared to the 82 SM of the current RTX 3090.
The difference between RDNA 3 and Lovelace is that the AMD GPU will be able to reach 160 Shader Units with a double chip, to think that NVIDIA will reach 144 with a single chip is at least quite unrealistic and more when we talk about the same node. Hence, we think that the configuration of 144 Shader Units could correspond to Hopper and not Lovelace, since it is said that Lovelace will be a multi-chip GPU.
Infinity Cache not only in RDNA 3, but also in Lovelace
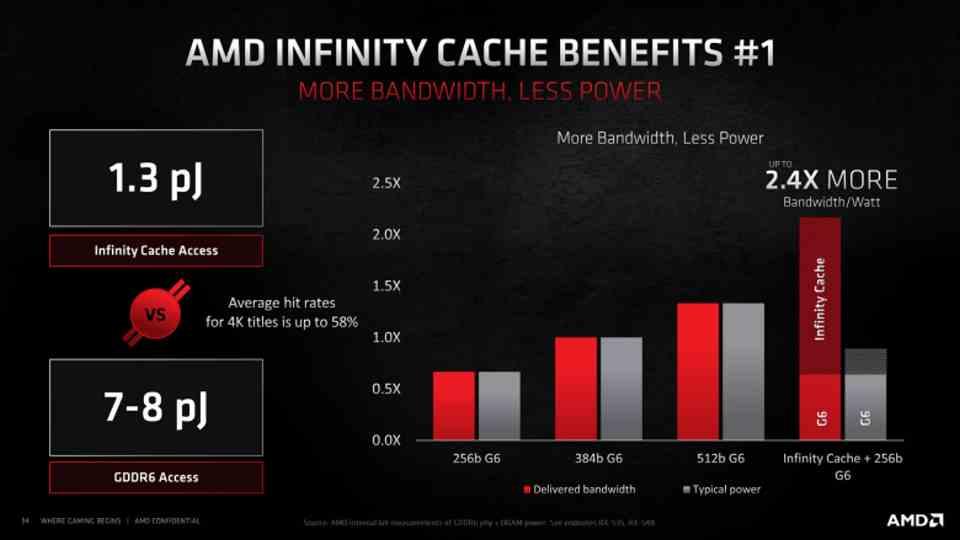
One of the points that makes us doubt about the huge number of SM drives that are rumored is the possibility that NVIDIA copies AMD’s idea of Infinity Cache to AMD, which serves so that the data discarded from L2 does not have to be recovered in RAM, the reason is that the energy consumption of doing so is much higher the further away any memory is from any processor as we have already mentioned several times.
So the big news from NVIDIA for Lovelace would be in adding an additional level of cache, which would do the same function as the Infinity Cache and would become a common point between RDNA 3 and Lovelace. The hints on adding a large L3 cache come from a recent NVIDIA paper and it would make all the sense in the world, as it is a way of not requiring large external bandwidths. We have the case of the AMD RX 6000 where its most powerful models use a 256-bit bus.
The addition of the L3 cache in Lovelace and the increase in it in RDNA 3 is what makes us think that the 144 SM configuration for Lovelace could be an exaggeration due to misinterpretation of the information that has been dropped by NVIDIA, but, we repeat, we may be wrong. In any case, we cannot forget that one of the strengths of the TSMC 5 nm node
Why does NVIDIA want an L3 cache in Lovelace?
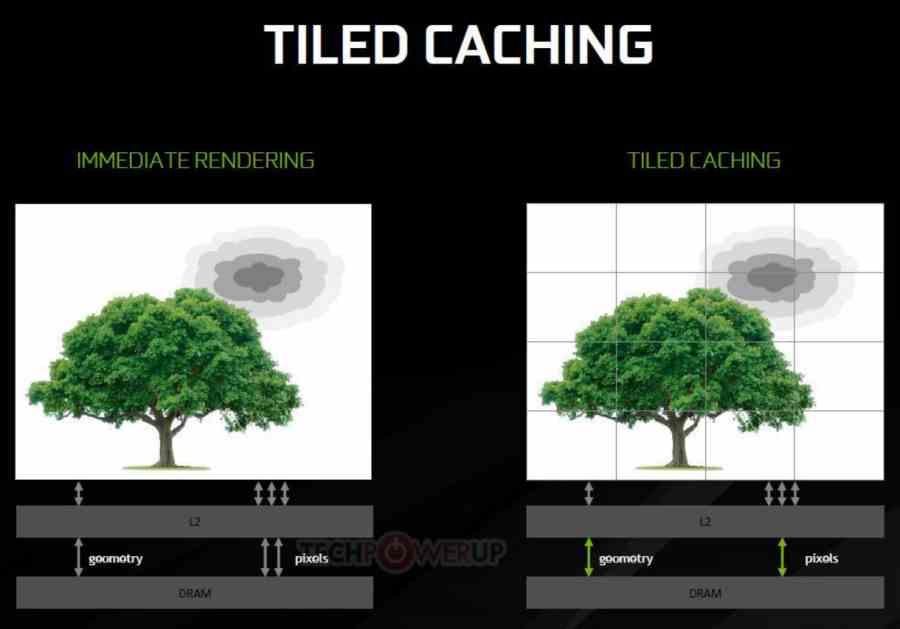
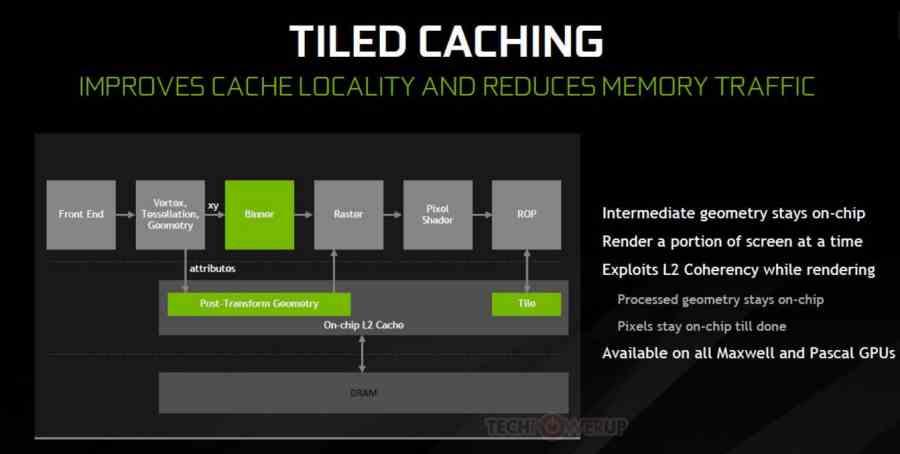
But what sense does it make for NVIDIA to do the same as AMD? Here comes one of the keys to performance, current NVIDIA GPUs from Maxwell to this day use what is called Tiled Caching, which consists of rasterizing the scene in the L2 cache directly. So it is very similar to Tile Rendering, but with two very important differences:
- Tile Rendering processes the tiles within an embedded memory that is controlled by the hardware, so the data does not drop out randomly until the tile has been finished.
- The Tile Rendering orders the geometry of the scene and generates a new screen list for each tile of the same before rasterizing the triangles. Tiled Caching does not.
In other words, Tiled Caching is a hybrid that in the first half of the pipeline works with a conventional GPU and the other half like a Tile Renderer but limited by depending on a cache, so the data often goes down, which means in many systems that go to DRAM. The solution? You add a very large cache to act as a mattress. Everything continues to operate on the L2 cache, but this L3 cache is there to make sure that we can recover the data faster and without energy consumption through the roof.
What AMD will copy Lovelace in RDNA 3

As for RDNA 3, we will see how they will adopt various ideas from the current NVIDIA RTX 30.
- The ratio of ALUs in FP32 per shader unit will be doubled, going from 64 to 128, equaling AMD with NVIDIA in this figure.
- New Ray Accelerator Unit, which can traverse the BVH tree without relying on the shader unit, this will be a huge improvement in Ray Tracing performance.
- The Matrix Core Unit of the CDNAs will be integrated into RDNA 3, this will allow algorithms based on convolutional neural networks similar to NVIDIA’s DLSS like the one Microsoft is developing.
On the other hand, there are going to be certain internal changes, for example the Wave64 mode that gave compatibility with GCN and has been key for the backward compatibility of the Xbox Series X and S, as well as of PlayStation 5 as it will disappear in RDNA 3 it will definitely say goodbye .