It has been many months (April) since we talked about the calls CUP-GPU Exascale from NVIDIA, which is nothing other than the name that Huang’s give to the call Composable On Package, a 2.5DIC or 3D integrated circuit (depending on the specific design, nothing new needs to be added) that would arrive with the Hooper architecture.
With this in mind, what could be the new GH100 chip based on this new architecture dedicated to DL and AI has been leaked, especially the first one, where as we already know, low-precision matrix mathematical performance prevails, or in other words , FP16. This chip has been specified with GPU-N and the seen certainly does not disappoint if we do not forget its end.
Two designs, two goals, one architecture

Just to review what we saw at the beginning of the year, what NVIDIA intends is to launch two different architectures focused on each purpose:
- Gaming -> Ada Lovelace
- DL and IA -> Hooper (MCM and monodie)
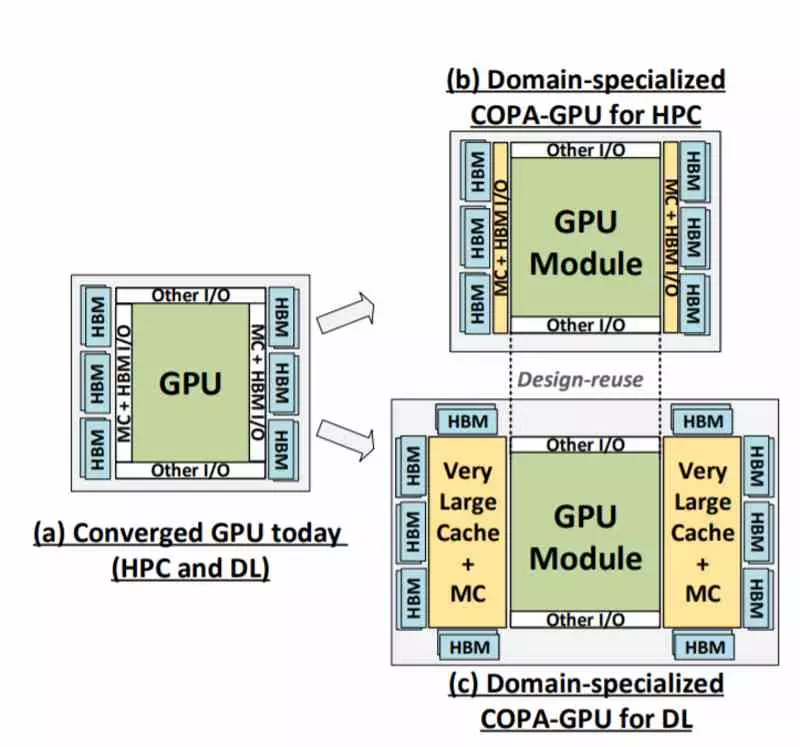
But within the latter there will be two different GPU designs that will be COPA and that differ in their capabilities and approaches. This supposed GPU-N would be focused on DL and therefore it would be the natural substitute for the current NVIDIA A100, which is important to understand the data that we are going to see now, since it is not an MCM GPU as such, but one of the modules exclusively, so it is understood that there will be multi die and mono die graphics cards.
Why is GPU-N behind AMD?
The mysterious GPU-N
Note: All benchmarks are run in NVArchSim, simulating GPU-N
High Accuracy for MLPerf WorkloadsComparison with other DL ASICs
(7 / x) pic.twitter.com/mxJExyILbM
– Redfire (@ Redfire75369) December 14, 2021
This graphics card is mono die, so from the outset it will be slower than the MI250X, but also its objective is not the AI as such, where for this if we would find MCM designs, this is different, it is one more market specific.
GPU-N will have 134 SM, which if the current structure in NVIDIA Shaders with Ampere is maintained, would give us nothing less than 8,576 Cores, or what is equal, a + 24% versus its predecessor. Given these data, it is logically speculated with the 5 nm of TSMC, but the frequency would instead remain at 1.4 GHz, curious to say the least. What will change is your L2, which will be increased to 60 MB (+ 50%) that together with the increase to 100 GB of HBM2E that it will have would give us a bandwidth (at the same frequency is understood) of 2.68 TB / s.
This is due to the 6144-bit bandwidth, which could mean sizes of more than twice the memory capacity. The problem with all this is that the comparison with the MI250X It is not really fair even if they share certain similarities, since this GPU-N would achieve 24.2 TFLOPs on FP32, only 24% more than the GPU it replaces.
Instead, it achieves 2.5 times the performance in FP16 with 779 TFLOPs And here is the important thing for the sector where it is directed. The AMD Instinct MI250X achieves 95.7 TFLOPs in FP32 and 383 TFLOPs at FP16 (-2.15x).
An upper-mid-range chip
GPU-N and COPA-GPU Configurations
SMs: 134
Frequency: 1.4 GHz
TFLOPs: 24.2 FP32, 779 FP16
L2: 60 MiB (to 1920 MiB)
DRAM Bandwidth: 2,687 TB / s (to 6.3 TB / s)
DRAM Capacity: 100 GiB (to 233 GiB)(8 / x) pic.twitter.com/v9ZJzzUBZl
– Redfire (@ Redfire75369) December 14, 2021
These data show that we are not facing the fastest GPU for NVIDIA DL, since the complete configuration of the die is expected to have 144 SM and no 134. We know this from the leaks of the supposed H100 that this is in charge of competing against the MI250X from AMD based on 288 SM with interposer and 18,432 Shaders.
So there we will see the potential of the architecture, but for now the data is promising for this sector and is not far from the improvement of 3x that we have been commenting on according to the leaks. Until it is presented as we well know, any resemblance to reality is pure coincidence, so let’s take this data with a little salt and be patient, since it could be presented in the CES2022.