Let’s assume that each thread of execution on the GPU is a viewer that enters the theater with a ticket to see a particular movie. It is an establishment with a single room, but which projects different films a day where each one of them represents an instruction with a duration in specific clock cycles. What the GPU scheduler does is sit the threads in their seats, which would be the registers, to resolve them, that is, it organizes and arranges the work of the execution thread. Meanwhile in the waiting room are the viewers of the next movie/instruction waiting to be executed.
What happens if the projection technician cannot show the film or a spectator is late? Since the projection time is limited, what is done is to send that group of threads back to the queue. Therefore, it is a type of architecture prepared to perform calculations with huge amounts of data in parallel, whether they are pixels, vertices or any other graphic primitive.
The warp concept
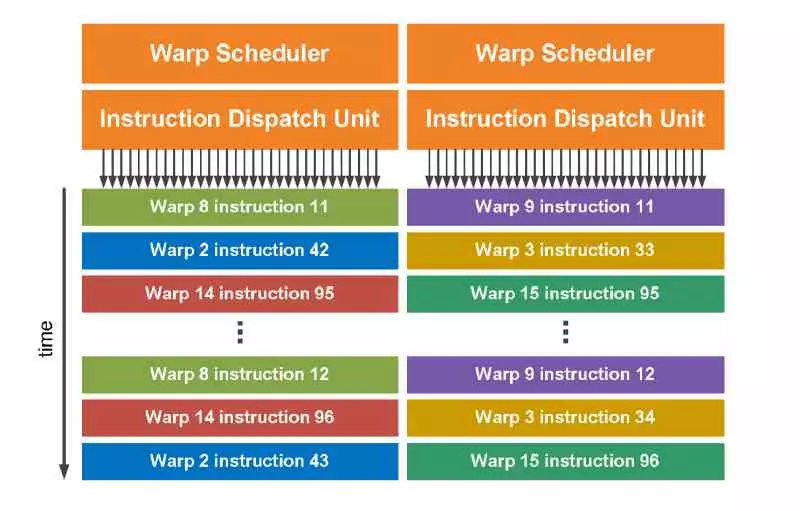
NVIDIA GPUs pool threads in blocks called Warpwhich can be of any size, but as a standard they are usually 32 threads each. These are stored in the registers of the subcore and are executed in a cascade where each group of the viewers that we have explained in the previous section enters in a group, these being a Warp.
It must be taken into account that each subcore can store several warps in its registers for their future execution, since these are distributed by the GPU command processor dividing the Threadgroups, which can be up to 1024 threads of execution. , limit set by DirectX.
What is subwarp interleaving?
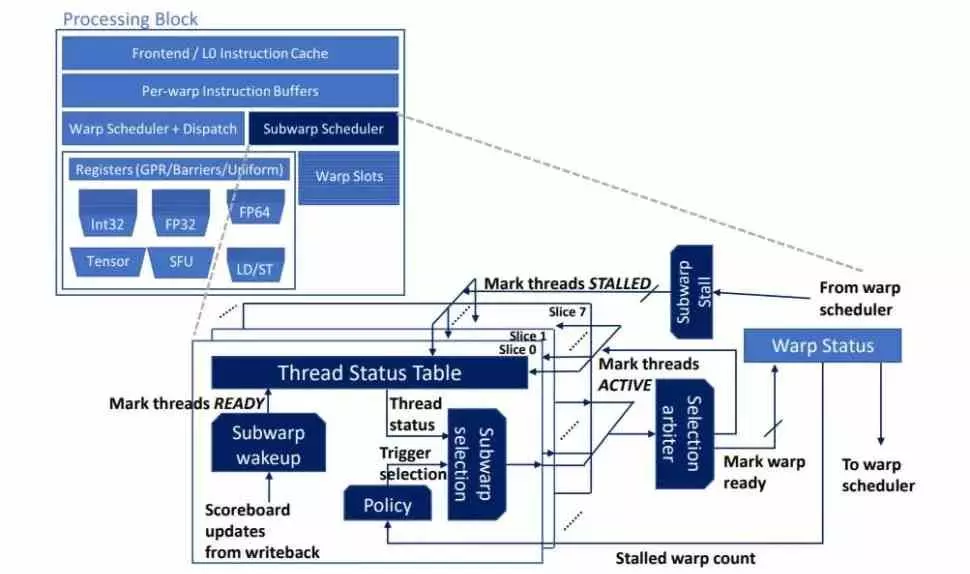
Through a paper published by NVIDIA itself, we have been able to learn of an improvement on its future architectures that will mean a change in the scheduler included in each of the subcores within the SM or shader units of each of its GPUs, but which integrates a concept with more than a decade that we have in CPU cores, the multithreading. Which will confuse many of you, therefore, it is important to bear in mind that at the hardware level we are facing two different concepts.
On a CPU multithreading is achieved duplicating the control unit of each of its cores, where the second unit of this type appears when a stop or bubble occurs, which arises when, due to latency with memory, the resolution of an instruction takes too long to arrive. In GPUs this is not due to the fact that they use the round-algorithmRobin, which consists of queuing unresolved threads and taking the next one. This is why graphics chips are said to be less dependent on latency than CPUs.
Well, subwarp interleaving is based on placing a double scheduler where the second one is activated when there is a stop or bubble in the GPU to grab the other Warp set stored in the registers. Which means not only duplicating the scheduler, but also the registers themselves for each subcore. All this to get a additional yield between 6.3% and 20% depending on the situation, at least that’s what NVIDIA claims.
What problem are you looking to solve?
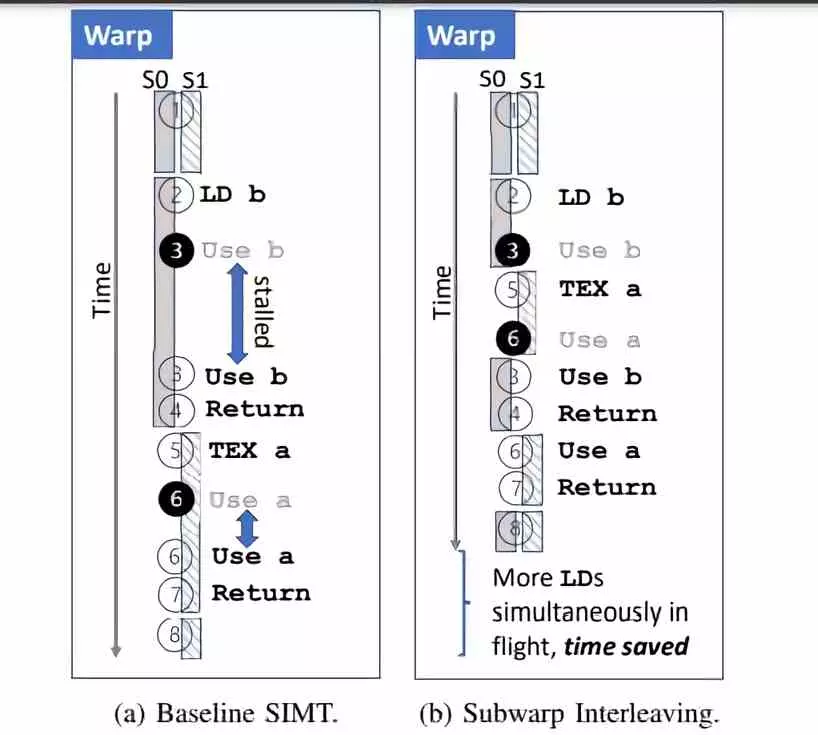
The change in subwarp interleaving is none other than power have 2 warps running simultaneously in each subcore of the SM of each GPU and each is its own program counter, which is another element of the control unit. If we take any current graphic architecture that has to execute two different Warps, we will see that these will execute them in series and therefore one after the other (example on the left in the image above). On the other hand, with the new method (right part of the image), what will happen is that if there is a stop in the first Warp, then it will switch to the second one immediately to speed up its execution. That’s why the name is interleaved subwarp.
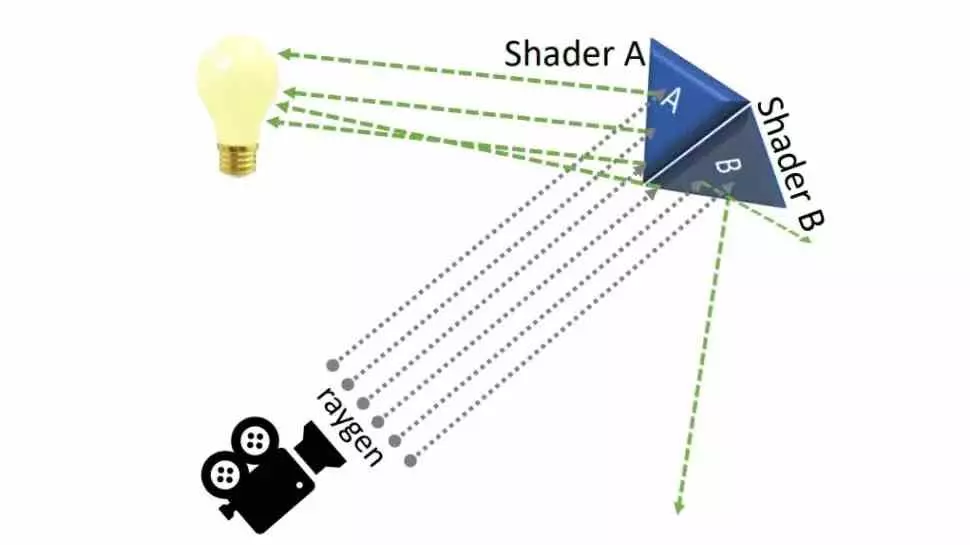
This has a specific utility for Ray Tracing, but for this we have to understand that once the RT Core has given the solution on whether or not the ray collides with the object, a shader is activated according to the Boolean condition that it returns. Therefore, two different shaders can be executed at the same time on the same surface, which would be executed separately, but with subwarp interleaving, when interleaved, it occurs in fewer clock cycles and, therefore, supposes an increase in the IPC in this aspect. .
Improvements not specified in the paper
One of the things that is not clear, but we are wondering, is if units that are idle will be able to benefit from subwarp interleaving? Especially the Tensor Cores, which despite their great speed are inactive for a good part of the time because they share the registers and the scheduler with the rest of the SM subcore. We may see new DLSS-style algorithms that work in parallel with the conventional SIMT execution of GPUs instead of switching as before.
Subwarp Interleaving for RTX 40

Since this change is at the hardware level, it cannot be applied to NVIDIA GPUs of families lower than the RTX 40 at the driver level, so we are going to see the subwarp interleaving being implemented in the Lovelace architecture, being the first important change that we know they have compared to previous generations.
In any case, it is curious to see a concept that has been implemented for more than ten years in Intel and AMD CPUs, but at the GPU level, which also makes us think that the typical latency hiding systems in this type of processor are they are falling behind. Let’s not forget that the price to pay for more bandwidth with newer VRAMs is always increased latency.